深入解析:PDF表格数据提取转Excel的五大实战方案及避坑指南
深入解析:PDF表格数据提取转Excel的五大实战方案及避坑指南
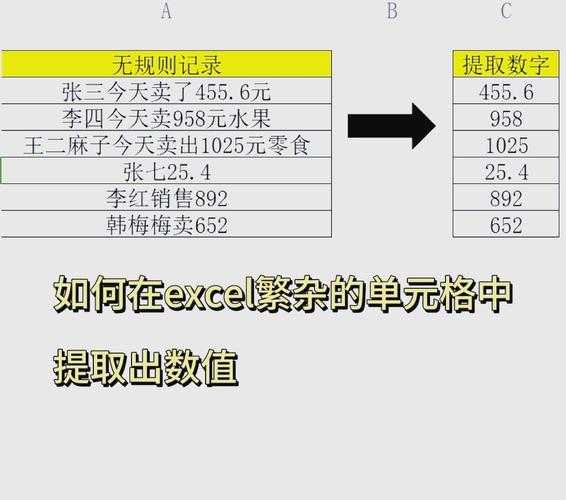
为什么你需要高效转换PDF表格?
作为财务分析师的李敏,上月花了8小时手动录入季度报表;项目经理小王因格式错乱被退回了三次报销单。这些真实痛点正是我们探讨pdf提取转excel解决方案的起点。当表格数据被困在PDF的静态牢笼里,你会选择做数据的"搬砖工"还是"炼金师"?PDF表格的三大类型与转换难点
尝试过将pdf表格数据提取到excel的职场人都懂:扫描件里扭曲的线条、合并单元格引发的错位、数字变成乱码的绝望。- 原生表格:由Office直接导出的完美结构
- 扫描图片:需要OCR识别的"硬骨头"
- 混合排版:表格嵌入文本中的"游击战"
四类实战解决方案深度测评
方案一:Windows平台黄金搭档 - Adobe Acrobat Pro
作为Windows生态的专业级解决方案,它能完美解决从pdf中提取表格到excel的需求。操作指南:
1. 右键PDF→打开方式→Acrobat Pro
2. 工具→导出PDF→电子表格→Excel工作簿
3. 关键设置:勾选"保留页面布局"
优势:在Windows平台保持原字体/公式/合并单元格
避坑技巧:
当处理多栏排版时,提前在Acrobat中使用"裁剪页面"分栏处理,可避免数据串行问题。方案二:免费利器 - Excel自带转换
若不想安装第三方工具,从pdf提取表格到excel可直接在Office365实现:1. Excel→数据→获取数据→自文件→从PDF
2. 选择需转换的表格
3. 加载前调整列格式
适用场景:简单财务报表/产品规格表
方案三:开发者的秘密武器 - Python自动化
import tabulatabula.convert_into("财务报告.pdf","输出.xlsx",output_format="xlsx",pages='all')进阶技巧:
添加area参数指定表格坐标可精确提取混合排版中的数据:area=[120,40,450,800] # 上,左,下,右
方案四:云端方案 - 小型PDF转换器
- 适合临时紧急任务
- 避开企业敏感数据上传风险
- OCR识别准确率超95%
扫描件处理秘诀:
转换前用Windows自带照片工具调整对比度+旋转矫正,识别准确率提升60%五大高频翻车现场急救方案
| 故障现象 | 根本原因 | Windows系统解决方案 |
|---|---|---|
| 数字变成日期 | 格式自动识别错误 | 加载前设置列格式为文本 |
| 表格四分五裂 | 分页表格未识别 | Acrobat中设置跨页识别 |
| 中文乱码 | 编码不匹配 | 转换时选择UTF-8编码 |
| 错位合并单元格 | 结构识别失败 | 使用Python指定区域提取 |
根据使用场景的终极选择建议
- 日常办公族:Excel自带转换+Acrobat互补
- 财务/HR高频用户:投资Adobe Acrobat Pro
- 技术开发人员:Python+Tabula黄金组合
• 本地处理保障数据安全
• 专业软件生态完善
• 系统级文件格式支持
特殊场景的进阶解决方案
面对财务合并报表中的多层表头嵌套结构:1. 先用Python导出原始数据
2. 用Excel Power Query重建层级
3. 关键步骤:建立关系映射表修复结构
效率倍增的三大必备技能
想专业地将pdf表格数据提取到excel?这三点不能不会:1. 掌握Excel数据清洗函数(TEXTSPLIT/FILTER)
2. 配置Windows右键菜单快捷转换
3. 建立标准化PDF模板避免格式灾难
上个月我帮客户用Python批量处理200份质检报告,3分钟完成原本2天的工作量。
未来工作台的智能升级路径
微软最新Power Automate可实现:• 邮件收到PDF→自动转换→存入指定Excel
• 每天8点自动生成数据简报
Windows系统深度整合能力让这种自动化流程开箱即用。
无论选择哪种pdf提取转excel方案,核心原则是:
简单表格交给工具,复杂数据善用组合方案。试试今天推荐的技巧,欢迎在评论区分享你的转换神器!