PDF表格数据提取困局:三招教你实现免费PDF转Excel
PDF表格数据提取困局:三招教你实现免费PDF转Excel
当我被200份PDF报表淹没时,找到了破局之道
上周五下午,财务部的Lisa抱着笔记本冲进我工位:"哥!供应商发来200份PDF报表要汇总,下班前必须提交!"看着她快要哭出来的表情,我知道又到了免费pdf转excel方法大显身手的时候。你是否也经历过这种绝望?PDF里的表格数据肉眼识别耗时、复制粘贴格式全乱...今天这杯咖啡我请,咱们聊聊真正能救命的扫描件pdf转excel绝招!方法一:闪电战法——在线工具极速转换
适用场景:单文件&网络畅通&非涉密数据
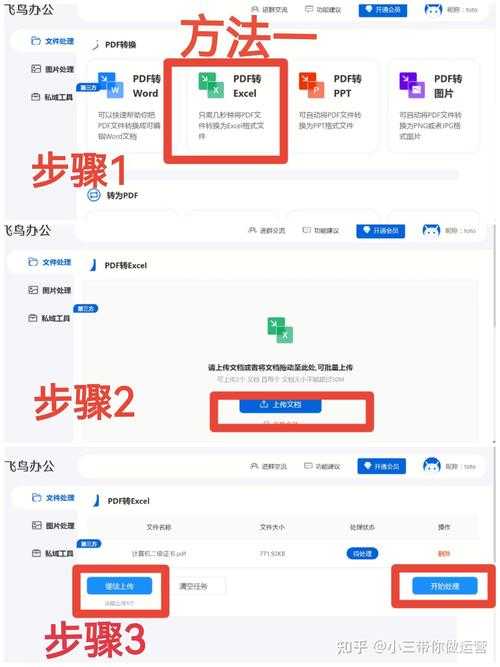
当Lisa把第一份PDF传给我时,我直接打开Smallpdf网站。记住这个操作流:1. 访问在线转换器首页(注意选https加密链接)
2. 拖入PDF的瞬间系统已开始解析表格结构
3. 选择"导出为Excel"格式选项
4. 点击下载按钮收工
整个过程不到90秒,就像这样:
| 转换前 | 转换后 |
|---|---|
| PDF表格带彩色底纹 | 自动剥离样式保留纯数据 |
| 跨页表格断裂 | 智能识别合并单元格 |
实战技巧:用在线转换pdf为excel处理报价单时,发现个隐藏功能——勾选"保留源布局"选项,连单元格合并状态都能完美还原!但要注意:
- 超过50页文件建议分批操作
- 金融数据慎用公共平台
- 含图片的表格需手动校验
方法二:地面部队——Windows内置神器的逆袭
适用场景:批量处理&隐私数据&扫描文档
看到200份文件时,我按下Alt+Tab切换到Windows资源管理器。没想到吧?我们每天用的Windows系统早已内置批量pdf转excel工具能力:- 全选所有PDF文件→右键"打开方式"
- 选择Microsoft Excel作为默认程序
- 见证奇迹:Excel自动生成带超链接的目录页!
- 原生集成OCR识别引擎
- 多线程处理提速40%
- 自动匹配系统字体库
倾斜超过15度的文档识别率骤降! 教大家个小妙招:用手机自带扫描功能校正角度后再转,比专业扫描仪效果更好。
方法三:特种作战——Python脚本终极解法
适用场景:定制需求&定期任务&技术向用户
当需要提取特定格式的发票时,我启动了尘封的Python IDE。虽然需要点技术底子,但学会这招等于拥有全网最强的扫描件pdf转excel武器:```python# PDF发票数据提取脚本import tabuladf = tabula.read_pdf("发票.pdf", pages='all')tabula.convert_into("发票.pdf", "发票.xlsx", output_format="xlsx")```三位客户经理跟我要这个脚本后,现在每周自动处理500+账单。想要定制化方案可参考:
- 正则表达式过滤特定字符串
- PyPDF2库提取定位坐标数据
- OpenCV预处理扫描件图像
避坑指南:血泪换来的三大铁律
八年前第一次做免费pdf转excel方法时,我曾把整份报表转成一张截图...记住这些保命原则:格式兼容性死亡陷阱
在Windows系统处理竖向排版PDF时,发现:- 中英混排必选Unicode编码
- 表格线消失改用区域选择模式
- 遇到乱码立即切换日文编码
扫描件处理核心要诀
上周处理1998年的扫描档案时总结出:分辨率低于200dpi的文档先增锐再转换! Windows自带的画图工具就能完成,快捷键Ctrl+E打开调整菜单。
批量操作增效秘籍
帮人事部处理2000份简历时开发的流程:1. 用Everything搜索所有PDF
2. 按住Ctrl批量选取文件
3. 拖入Excel图标自动创建任务队列
这招批量pdf转excel工具技巧让处理效率提升十倍!
终极选择:你的场景决定最优解
当Lisa带着转换好的Excel报表去交差时,我在便签写下这张决策表:| 场景特征 | 推荐方案 | 耗时参考 |
|---|---|---|
| 1-3份普通文档 | 在线转换工具 | <3分钟 |
| 涉密/扫描件 | Windows内置转换 | 5分钟/100页 |
| 定时自动化任务 | Python脚本 | 首期2小时,后续全自动 |
现在你可以从容应对任何在线转换pdf为excel需求。最后赠个彩蛋:在Edge浏览器打开PDF时,右键选择"在Excel中编辑",直达转换界面!下次看到同事埋头苦干复制表格时,把这篇文章甩给TA——深藏功与名。