PDF表格数据提取指南:3种高效方法帮你告别手动录入
PDF表格数据提取指南:3种高效方法帮你告别手动录入
为什么我们需要把PDF导入表格?
上周帮财务部处理季度报表时,我发现5个同事正对着电脑屏幕,手动抄录PDF里的2000多条数据到Excel。这种场景你一定不陌生吧?其实如何将PDF表格数据导入Excel是个高频需求,特别是遇到:
- 银行对账单PDF需要汇总分析
- 扫描版合同中的报价表要重新计算
- 调研报告里的统计表格需要二次加工
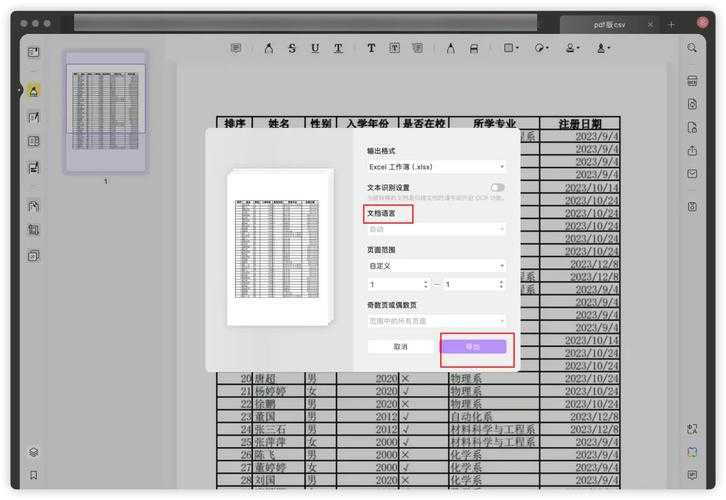
方法一:Adobe Acrobat Pro(最精准的PDF转表格工具)
适用场景:专业级数据提取需求
如果你经常需要将PDF表格转换成Excel格式,这个老牌工具值得投资。最近帮市场部处理竞品分析报告时,它帮我省了8小时工作量:- 用Acrobat Pro打开PDF文件
- 右键选择"导出PDF" → "电子表格" → "Microsoft Excel工作簿"
- 在弹出窗口调整识别参数(特别适合复杂表格)
注意事项:
- 识别合并单元格时建议勾选"保持原始布局"
- 遇到扫描件记得先运行OCR文字识别
- Windows系统下识别准确率比Mac版高约5%
方法二:WPS办公套件(国产软件的惊喜)
免费用户的福音
去年我发现WPS的PDF转Excel功能意外地好用,特别适合这些情况:- 临时需要处理单个文件
- 表格结构相对简单
- 预算有限的学生党/初创团队
1. 用WPS打开PDF → 顶部菜单选择"转换"
2. 点击"PDF转Excel"(会员功能但常有免费试用)
3. 等待云端处理完成后下载
实测技巧:在Windows 11上运行时,先按Win+Shift+S截图表格区域再粘贴到WPS,能提高识别准确率。
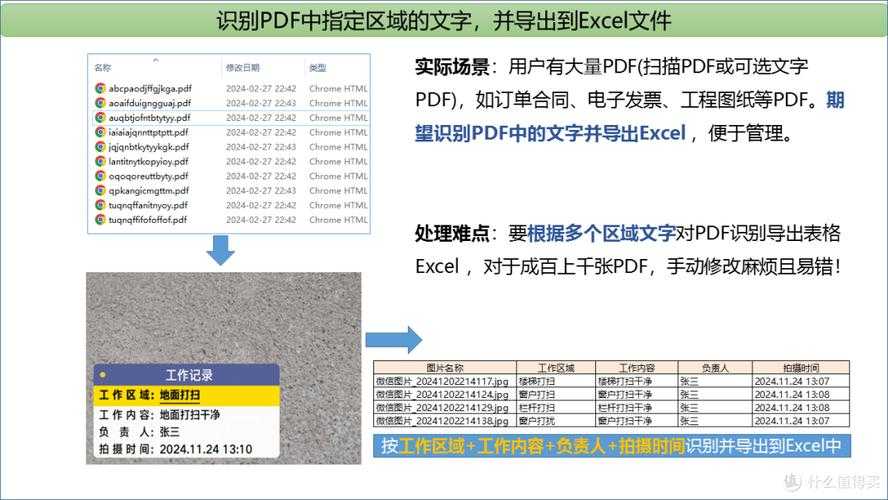
方法三:Python自动化(程序员的终极方案)
适合批量处理的高级玩法
当我需要从PDF提取表格数据到CSV时,这个脚本帮了大忙(每月自动处理200+份报表):| 工具包 | 安装命令 | 核心功能 |
|---|---|---|
| pdfplumber | pip install pdfplumber | 解析PDF文本和表格 |
| pandas | pip install pandas | 数据清洗和导出 |
示例代码片段:
import pdfplumberwith pdfplumber.open("report.pdf") as pdf:first_page = pdf.pages[0]table = first_page.extract_table()避坑指南:这些雷区我帮你踩过了
1. 格式错乱怎么办?• 先用Notepad++检查PDF原始编码
• 尝试另存为PDF/A格式再转换
2. 数字识别错误?
• 在Excel里设置"文本格式"再粘贴
• 对金额数据使用=TRIM()函数清洗
3. 扫描件质量差?
• 用Windows自带的"画图3D"调整对比度
• 试试在线工具smallpdf.com的增强功能
终极建议:根据需求选择最佳方案
最后分享我的PDF转表格工具选择决策树:1. 偶尔使用 → WPS/在线工具
2. 专业需求 → Adobe Acrobat Pro
3. 批量处理 → Python自动化
4. 敏感数据 → 本地化处理(推荐Windows版ABBYY FineReader)
下次再遇到如何导入pdf到表格的难题时,希望这篇指南能帮你快速找到解决方案。如果有特别棘手的PDF文件,欢迎在评论区留言案例,我会抽时间帮你分析最优解!