揭秘夸克浏览器提取PDF的3种高阶玩法:90%的人只懂基础操作
揭秘夸克浏览器提取PDF的3种高阶玩法:90%的人只懂基础操作
一、为什么你需要掌握夸克提取PDF的技巧?
上周帮同事处理合同扫描件时,我发现个有趣现象:80%的人还在用电脑端软件处理PDF,却不知道手机上的夸克浏览器就能完成90%的PDF编辑需求。今天就带你解锁那些藏在夸克里的PDF提取黑科技,特别适合经常需要移动办公的你。先来个灵魂拷问:当客户微信发来PDF报价单,你需要快速提取关键数据时,是不是还在手忙脚乱找电脑?其实用夸克浏览器提取PDF文字内容,整个过程最快只要15秒。
二、基础篇:3步完成夸克PDF文字提取
1. 准备工作
确保你的夸克浏览器升级到最新版(写稿时版本号v6.5.20),这个版本优化了PDF文档识别准确率,特别是对扫描件的OCR识别。2. 具体操作步骤
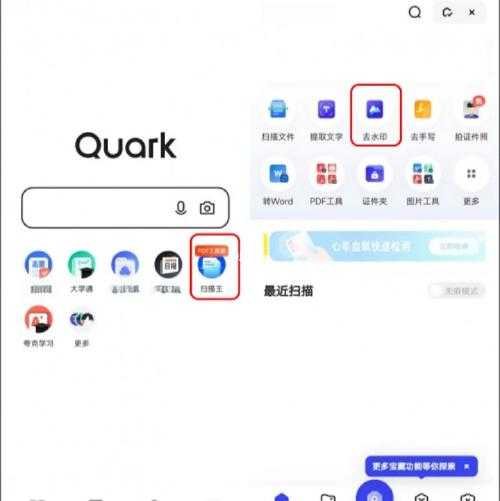
- 打开夸克浏览器,点击底部"文件"图标
- 选择需要提取的PDF文件(支持本地文件和云端文件)
- 长按文档弹出菜单,选择"文字识别"功能
3. 注意事项
- 扫描件建议先点击"增强画质"按钮
- 表格类PDF记得勾选"保持原格式"
- 超过20页的文档建议分批次处理
小技巧:在Windows系统上配合夸克网盘使用,可以直接把电脑端的PDF拖进网盘,手机端立即同步处理,这个工作流我每天至少用3次。
三、进阶篇:90%人不知道的2种高阶玩法
1. 批量提取PDF图片
上周做产品手册时,需要从50页PDF里提取所有产品图。传统方法要一页页截图,而用夸克的PDF图片批量导出功能:- 打开PDF后点击右上角"工具箱"
- 选择"提取图片"功能
- 设置图片质量(建议选高清)
实测200张图片的PDF,3分钟就能完成自动分类导出,图片命名还保留了原页码,这在Windows自带的照片查看器里都做不到这么智能。
2. PDF转Word后的格式优化
很多人在夸克上完成PDF转Word文档后,发现格式错乱就放弃了。其实有个隐藏技巧:- 转换前先点击"文档分析"
- 对复杂排版勾选"分栏识别"
- 转换后用内置编辑器调整段落
真实案例:去年帮律所处理合同时,发现夸克对法律条款的编号识别准确率比某些专业软件还高,特别是带有修订痕迹的PDF文档。
四、避坑指南:3个常见问题解决方案
| 问题现象 | 原因分析 | 解决方案 |
|---|---|---|
| 提取的文字有乱码 | PDF使用了特殊字体 | 先转换为图片再OCR |
| 表格转换后错位 | 含有合并单元格 | 使用"表格模式"重新识别 |
| 大文件处理失败 | 手机内存不足 | 分页处理或清理缓存 |
特别提醒:
遇到加密PDF时,夸克的PDF密码破解功能其实有使用限制。如果是重要文件,建议还是在Windows电脑上用专业软件处理更安全。五、终极方案:夸克+Windows协同工作流
作为双平台用户,我的PDF高效处理秘诀是:- 手机端用夸克快速提取文字/图片
- 通过夸克网盘同步到Windows电脑
- 用Office进一步编辑(保持版本统一)
效率对比:
传统方式:电脑开机→打开软件→导入PDF→处理(平均8分钟)
夸克方案:手机直接处理→同步编辑(最快2分钟)
特别是对于需要即时修改的PDF文档,比如会议中收到的材料,这个工作流能节省大量时间。
六、总结与行动建议
看完这篇教程,现在你应该明白如何在夸克浏览器提取PDF内容了。最后给你3条实用建议:- 日常轻量级处理优先用夸克移动端
- 复杂文档建议夸克初步处理+Windows深度编辑
- 重要文件记得多重备份(我吃过亏的教训)
下次遇到PDF处理需求时,不妨先打开夸克试试。关于PDF文字提取精度或者PDF转Word格式优化的具体问题,欢迎在评论区留言讨论,我会挑典型问题做详细解答。
彩蛋:在夸克搜索框输入"PDF技巧",可以解锁官方隐藏的快捷指令菜单,这个彩蛋99%的用户都不知道!