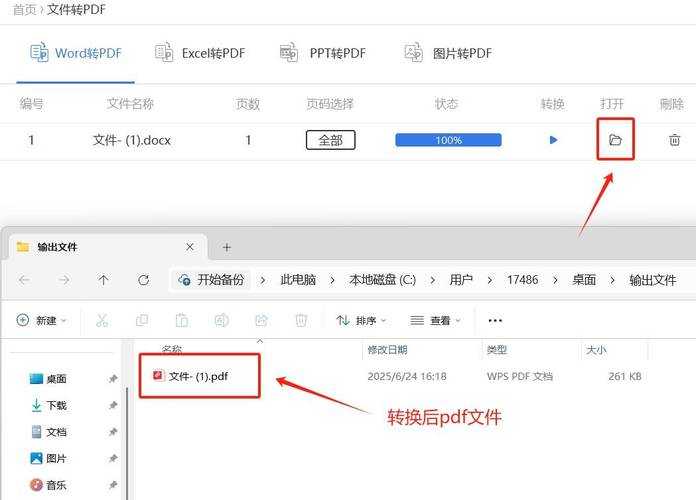
PDF转TXT格式的深度实践:从手动操作到批量处理的高效路径
PDF转TXT格式的深度实践:从手动操作到批量处理的高效路径
引言:为什么你需要关注PDF转TXT格式的质量?
你好,我是老张,一个在技术圈摸爬滚打多年的老码农。今天我们不聊那些高大上的概念,就来解决一个实实在在的问题:如何高质量地完成**PDF转TXT格式**的任务。相信你和我一样,在工作中无数次遇到需要从PDF中提取文字信息的情况——可能是处理扫描的合同、下载的电子书,或是同事发来的报告。但你是否遇到过这样的困扰:转换后的TXT文件乱码一堆,段落全挤在一起,或者干脆就是一片空白?这背后其实涉及到PDF文件的内在复杂性。今天,我就带你深入探讨几种**PDF转TXT格式的方法**,从最基础的手动操作到专业的批量处理,帮你找到最适合自己的解决方案。
核心观点: 一次高质量的**PDF转TXT格式的转换**,不仅能节省你大量的编辑时间,更能保证信息的完整性和准确性。这绝不是简单的“另存为”就能解决的问题。
PDF转TXT格式的底层逻辑:为什么它不简单?
PDF文件的两种类型
在开始实际操作前,我们需要先理解PDF文件的本质。简单来说,PDF可以分为两大类:- 文本型PDF: 文件内部包含可选择的文字层,这是最容易转换的类型。
- 图像型PDF: 本质上是图片的集合(如扫描件),需要OCR(光学字符识别)技术才能提取文字。
正是这种差异导致了**PDF转TXT格式的转换效果**千差万别。很多人抱怨转换效果差,往往是因为没有区分对待这两种不同类型的PDF文件。
编码与格式的挑战
另一个常见问题是字符编码。PDF可能使用特殊的字体或编码,如果在转换过程中没有正确识别,就会产生乱码。此外,PDF中的复杂排版(如分栏、表格、页眉页脚)也会给**PDF转TXT格式的软件**带来巨大挑战。实战方案:三种PDF转TXT格式的方法对比
方法一:使用在线转换工具(适合临时、少量需求)
对于偶尔需要转换一两个文件的情况,在线工具是最便捷的选择。它们无需安装,打开浏览器就能使用。操作步骤:
- 打开任意一个PDF在线转换网站
- 上传你的PDF文件
- 选择输出格式为TXT
- 下载转换后的文件
优点: 方便快捷,适合临时需求
缺点: 文件需要上传到第三方服务器,有隐私风险;对文件大小通常有限制;批量处理效率低
小技巧: 如果PDF是扫描件,记得选择带有OCR功能的在线工具,否则你得到的可能是一个空白的TXT文件。
方法二:使用专业桌面软件(适合高质量、批量需求)
当你有大量文件需要处理,或者对转换质量有较高要求时,专业桌面软件是更好的选择。在**Windows**系统环境下,有很多优秀的工具可以选择。以Adobe Acrobat Pro为例,它在**Windows**平台上的表现尤为出色:
- 打开PDF文件后,选择“文件”>“导出到”>“文本”
- 在设置中可以选择保留页面布局或仅保留纯文本
- 对于扫描件,可以使用“增强扫描”功能提升OCR精度
实际案例: 我曾经需要处理一批扫描版的技术手册,大约有200多个PDF文件。使用**Windows**自带的Powershell脚本结合专业软件,我实现了全自动的批量**PDF转TXT格式的转换**,节省了至少8个小时的手动操作时间。
专业建议: 如果你经常需要处理这类任务,投资一款专业的**PDF转TXT格式的软件**是值得的,它们通常提供批量处理、格式保持等高级功能。
方法三:编程实现(适合技术用户、定制化需求)
对于开发者或者有特殊需求的用户,通过编程实现**PDF转TXT格式**提供了最大的灵活性。Python是目前最受欢迎的选择,因为有丰富的库支持。基础代码示例(使用Python的pdfplumber库):
import pdfplumberwith pdfplumber.open('input.pdf') as pdf:text = ''for page in pdf.pages:text += page.extract_text() + '\n'with open('output.txt', 'w', encoding='utf-8') as f:f.write(text)这种方法的好处是你可以完全控制转换过程,比如自定义段落分割规则、过滤特定内容等。在**Windows**系统上配置Python环境后,你还可以结合批处理文件实现一键转换。
避免常见陷阱:PDF转TXT格式的质量控制
乱码问题的解决
乱码是**PDF转TXT格式**中最常见的问题之一。解决方案包括:- 确保转换工具支持UTF-8编码
- 对于中文PDF,选择支持中文OCR的工具
- 在编程实现中明确指定正确的编码格式
格式保持的技巧
完全保持PDF的原始格式几乎是不可能的,但我们可以通过以下方法提升可读性:- 在转换前,使用PDF工具的“优化扫描”功能提升图像质量
- 选择“保留布局”选项(如果可用)
- 通过正则表达式对转换后的文本进行后处理
批量处理的效率优化
当你需要处理大量文件时,效率变得至关重要。在**Windows**环境下,你可以:- 使用支持命令行调用的转换工具,然后通过批处理脚本自动化
- 利用**Windows**任务计划程序在系统空闲时执行转换任务
- 对文件进行预处理,按类型分类后采用不同的转换策略
总结与建议:选择适合你的PDF转TXT格式方案
通过今天的探讨,相信你对**PDF转TXT格式**有了更深入的理解。无论你是偶尔需要转换一两个文件的普通用户,还是需要处理大量文档的专业人士,都能找到适合自己的解决方案。我的个人建议:
- 对于偶尔使用的普通用户:选择可靠的在线工具或**Windows**系统自带的打印到文本功能
- 对于经常需要处理文档的办公人员:投资一款专业的桌面软件,如Adobe Acrobat Pro
- 对于开发者或技术爱好者:学习使用Python等编程语言实现定制化转换
最后的小提示: 在进行重要的**PDF转TXT格式**任务前,务必先用样本文件测试转换效果。这样可以避免批量处理完成后才发现质量问题,造成时间浪费。
希望这篇文章能帮你解决实际工作中的问题。如果你有更好的**PDF转TXT格式**技巧或遇到特殊问题,欢迎在评论区分享交流!