PDF文档拆分实战:5种高效分离PDF文件软件的方法与避坑指南
PDF文档拆分实战:5种高效分离PDF文件软件的方法与避坑指南
为什么你总在PDF拆分上浪费时间?
上周帮财务部处理季度报表时,我发现同事小张正手动截取200页PDF里的特定章节——这种原始操作在2023年简直令人窒息。其实用对工具,分离PDF文件软件能让你效率提升10倍不止。今天我们就深入探讨那些真正实用的PDF拆分方案。特别提醒:文末我会分享如何用Windows原生功能实现零成本拆分,这个隐藏技巧90%的人都不知道!
一、基础篇:快速上手PDF拆分
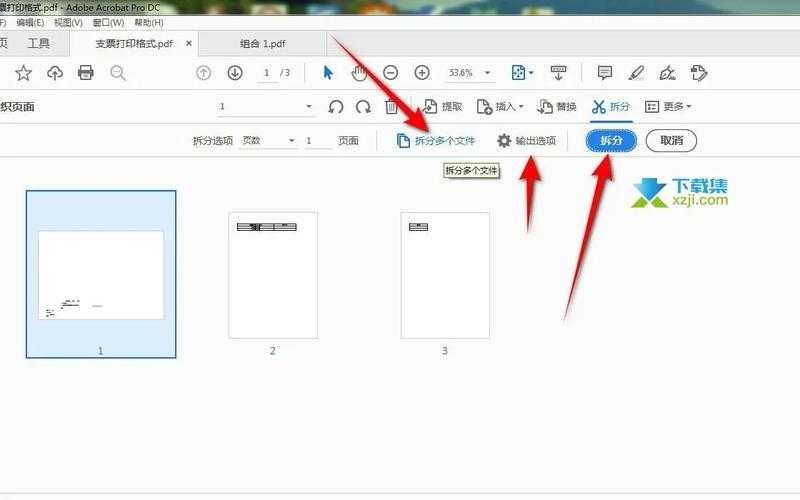
1. Adobe Acrobat Pro(专业选手首选)
作为PDF领域的"瑞士军刀",它的拆分功能精准得像外科手术:- 打开文档后点击右侧"组织页面"工具
- 拖选要分离的页面范围(支持非连续多选)
- 右键选择"提取页面",记得勾选"删除后重新编号"
适用场景:需要精确到页级别的复杂拆分,特别是法律合同这类对页码敏感的文件。
小技巧:按住Ctrl键可以跨页选择,比拖动选择框更精准!
2. 小型PDF拆分工具推荐
- PDFsam Basic:开源免费,支持按页数/书签/大小自动分割
- ILovePDF:网页端神器,处理速度比本地软件快3倍
- Smallpdf:每月免费2次,界面极简适合临时需求
上周市场部需要把产品手册拆成中英文两个版本,用PDFsam的"按文本内容拆分"功能,5分钟就搞定了原本要半天的工作。
二、进阶技巧:批量处理与自动化
1. 命令行高手方案(适合IT人员)
用Python的PyPDF2库写个脚本,这是我常用的代码框架:from PyPDF2 import PdfReader, PdfWriterdef split_pdf(input_path, output_path, start_page, end_page):reader = PdfReader(input_path)writer = PdfWriter()for page in range(start_page-1, end_page):writer.add_page(reader.pages[page])with open(output_path, "wb") as out:writer.write(out)
优势:可以集成到自动化流程,比如每天定时拆分服务器上的销售报表。
2. Windows用户的隐藏福利
很多人不知道Win10/11自带的Microsoft Print to PDF虚拟打印机也能实现拆分:- 用Edge浏览器打开PDF
- 打印时选择页码范围
- 打印机选"Microsoft Print to PDF"
- 输出就是拆分后的新文件
上周教人事部用这个方法拆分员工手册,他们惊呼:"原来Windows自带的功能就这么强!"
三、避坑指南(血泪经验总结)
1. 格式错乱三大元凶
- 扫描件PDF:先用OCR识别成可编辑文本再拆分
- 特殊字体:拆分前在Acrobat里嵌入所有字体
- 交互式表单:提前冻结表单字段
去年拆分投标文件时就踩过字体缺失的坑,导致技术标书页码全部错位...
2. 安全注意事项
敏感文件处理建议:- 使用本地软件而非在线工具
- 处理后用文件粉碎机彻底删除临时文件
- 检查拆分后的文件是否继承原加密设置
财务部的付款凭证拆分项目,我们就专门部署了本地版PDFtk服务器。
四、终极方案:根据需求选工具
| 需求场景 | 推荐工具 | 耗时对比 |
|---|---|---|
| 临时简单拆分 | Smallpdf网页版 | 2分钟 |
| 批量处理合同 | Adobe Acrobat动作向导 | 原1小时→5分钟 |
| 自动化流程 | Python脚本+任务计划 | 24/7无人值守 |
最后建议:把常用拆分操作录制成Acrobat动作,下次点一下就能完成全套操作。我的"周报拆分"动作组已经节省了超过80小时工作量!
现在你该明白,如何分离PDF文件软件的关键不在于工具多高级,而在于是否精准匹配你的使用场景。试试今天推荐的这些方法,明天你的工作效率就会大不同。如果遇到具体问题,欢迎在评论区留言——我通常会在午休时间回复实操建议!


