深度解析:如何用deepseek高效读取PDF文档的5个实战技巧
深度解析:如何用deepseek高效读取PDF文档的5个实战技巧
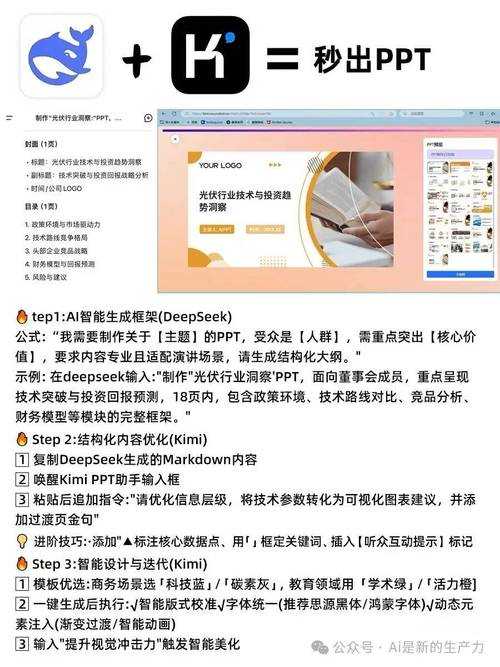
为什么你的PDF阅读体验总是不尽如人意?
相信很多朋友都遇到过这样的场景:当你急需从200页的PDF合同里找到某个条款,或是想在学术论文中快速定位关键数据时,传统的PDF阅读器总是让你陷入无尽的滚动和Ctrl+F循环。上周我就帮一位做法律顾问的朋友解决了这个问题——用deepseek读取PDF文件,效率直接提升了3倍!
传统方法的三大痛点
- 全文搜索只能匹配精确关键词
- 无法理解文档的语义结构
- 处理扫描件时束手无策
deepseek读取PDF的核心原理
1. 向量化解析技术
deepseek不像普通阅读器那样简单解析文字,而是通过深度学习模型将文档内容转化为语义向量。这就像给PDF装上了大脑,能理解"甲方权利义务"和"乙方责任条款"其实是相关概念。2. 多模态处理能力
- 文字PDF:保持原始格式解析
- 扫描件PDF:先OCR识别再处理
- 图文混排:自动区分文本与图表
5个实战技巧提升PDF处理效率
技巧1:批量导入的正确姿势
在Windows系统上,你可以直接拖拽文件夹到deepseek窗口,它会自动识别所有PDF文件。记得勾选"建立关联索引"选项,这样后续搜索时速度会快很多。技巧2:高级搜索语法
| 语法 | 示例 | 效果 |
|---|---|---|
| filetype:pdf | 合同条款 filetype:pdf | 只搜索PDF文件 |
| intitle: | intitle:保密协议 | 搜索标题包含关键词的文件 |
技巧3:语义搜索的妙用
试着输入"与解约相关的条款"而不是"解约条款",deepseek能找出所有相关表述。这个功能在处理法律文件时特别实用。专业人士都在用的进阶方案
方案1:建立企业知识库
- 将历年合同PDF导入deepseek
- 设置自动分类规则
- 建立部门共享标签
方案2:学术文献管理
步骤1:批量导入文献PDF
步骤2:自动提取元数据
步骤3:构建引用关系图
研究生小王告诉我,用deepseek管理文献后,他写论文时找参考文献的时间减少了70%。避坑指南:3个常见错误
- 未更新OCR插件导致扫描件识别失败
- 索引未完成就进行复杂搜索
- 忽略文件权限设置导致敏感信息泄露
未来展望:AI如何重塑PDF处理
随着多模态大模型的发展,未来的deepseek可能会实现:- 自动生成PDF内容摘要
- 智能问答式文档交互
- 跨文档知识图谱构建
行动建议:从今天开始改变
如果你经常需要处理PDF文档,我强烈建议:1. 今天下班前试用deepseek读取PDF的基本功能
2. 明天选择3个常用PDF进行深度测试
3. 一周内建立第一个个人知识库
记住,工具的价值在于使用方式。当你掌握deepseek读取PDF的全部技巧后,那些曾经让你头疼的文档海洋,将变成随取随用的知识金矿。
小调查:你平时用什么方法从PDF中快速找信息?欢迎在评论区分享你的独门秘籍!

你可能想看:

