PDF分拆实战指南:从基础操作到高阶技巧的全方位解析
PDF分拆实战指南:从基础操作到高阶技巧的全方位解析
为什么你需要掌握PDF分拆这项技能?
上周有个做财务的朋友跟我吐槽,她收到一个200多页的供应商合同PDF,但只需要其中5个关键章节发给不同部门。手动截图再拼接?光是想到这个操作我就头皮发麻!其实像这样的场景太常见了:
- 律师需要从案卷中提取特定证据页
- HR要把新员工手册拆成单个政策文件
- 学生想保存教材里的重点章节
基础篇:人人都该掌握的3种PDF分拆方法
1. 用Windows自带的打印功能(最容易被忽略的免费方案)
你知道吗?Windows系统自带的Microsoft Print to PDF虚拟打印机就能实现基础分拆。具体步骤:- 用任意PDF阅读器打开文件
- 在打印界面选择"Microsoft Print to PDF"
- 在页面范围输入想提取的页码(比如1-3,5,7-9)
- 保存为新文件即可
2. Adobe Acrobat的专业玩法(精准到页面的分割)
如果你经常需要按特定页面拆分PDF文件,建议使用Adobe Acrobat的"组织页面"功能:- 右键点击缩略图选择"提取页面"
- 可以设置"提取后删除"实现真分拆
- 还能批量设置分割规则(比如每5页一个文件)
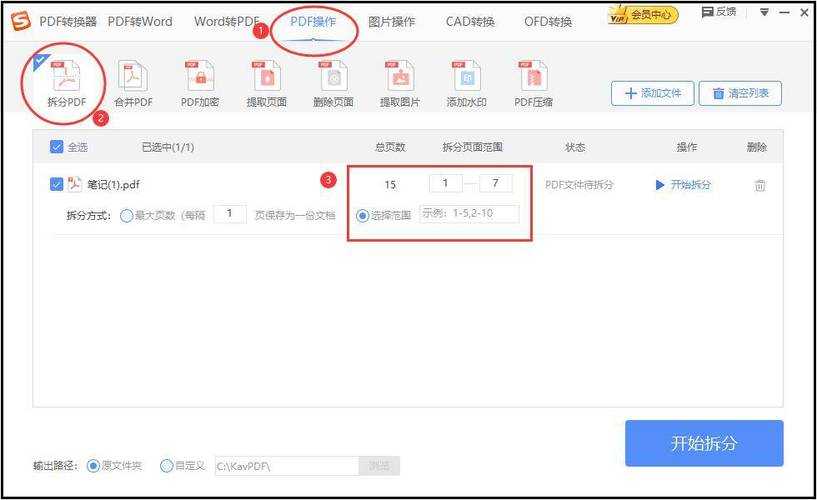
3. 在线工具的轻量解决方案(跨平台首选)
推荐Smallpdf这个神器,它的PDF分拆功能简单到令人发指:- 拖拽文件到网页
- 用滑块选择要分割的范围
- 支持按页数/文件大小/书签自动分割
- 下载处理后的文件
进阶篇:高手都在用的3种特殊分拆技巧
1. 命令行自动化(IT运维必备)
用Python的PyPDF2库写个脚本,可以批量处理上百个文件:import PyPDF2reader = PyPDF2.PdfReader("input.pdf")for i in range(len(reader.pages)):writer = PyPDF2.PdfWriter()writer.add_page(reader.pages[i])with open(f"page_{i+1}.pdf", "wb") as f:writer.write(f)这个方案特别适合需要定期拆分PDF报告的场景,设置好定时任务就全自动运行了。2. 按内容分拆(OCR+关键词识别)
有些PDF是扫描件没有文字层,这时候需要:- 先用ABBYY FineReader做OCR识别
- 通过关键词定位分割点(比如"CHAPTER")
- 再结合Adobe的动作脚本实现自动分割
3. 混合分拆法(综合应用场景)
遇到复杂情况时,我通常这样操作:- 先用PDF-XChange Editor提取大段落
- 再用AutoHotkey编写自动化流程
- 最后用7-Zip批量压缩分拆后的文件
避坑指南:PDF分拆常见的5个雷区
- 格式丢失:某些工具分拆后表格样式会错乱,建议先用专业工具测试
- 权限问题:加密的PDF需要先解除限制(合法用途)
- 扫描件处理:没有文字层的PDF要先做OCR识别
- 批量命名:分拆后文件建议用"原文件名_页码"格式
- 版本兼容:高版本PDF在低版本阅读器可能显示异常
终极建议:根据需求选择最佳方案
如何将PDF分拆最有效率?我的建议是:| 使用场景 | 推荐工具 | 耗时参考 |
|---|---|---|
| 偶尔简单分拆 | Windows打印功能 | 1分钟/文件 |
| 常规办公需求 | Adobe Acrobat | 30秒/文件 |
| 批量自动处理 | Python脚本 | 0.1秒/页 |
如果你有更特殊的PDF分拆需求,欢迎在评论区留言,我会一一解答~