PDF合并如何不压缩?3种无损合并方法全解析
PDF合并如何不压缩?3种无损合并方法全解析
为什么你的PDF合并后画质变差了?
上周有个做设计的朋友跟我吐槽,他用在线工具合并PDF方案时,200MB的文件硬是被压缩到20MB,客户发来的高清设计稿全糊了。这其实就是大多数PDF合并工具的默认设置:自动压缩以减小文件体积。但对我们这些需要保持原始质量的用户来说,简直是个灾难!今天我们就来聊聊如何实现PDF合并不压缩这个看似简单却暗藏玄机的需求。
PDF合并不压缩的核心痛点
- 合同扫描件合并后文字模糊
- 设计稿合并后色彩失真
- 学术论文插图合并后分辨率下降
- 合并后的文件无法满足印刷要求
方法一:用Adobe Acrobat专业版无损合并
具体操作步骤
- 打开Acrobat点击"工具"→"合并文件"
- 拖入需要合并的PDF文件
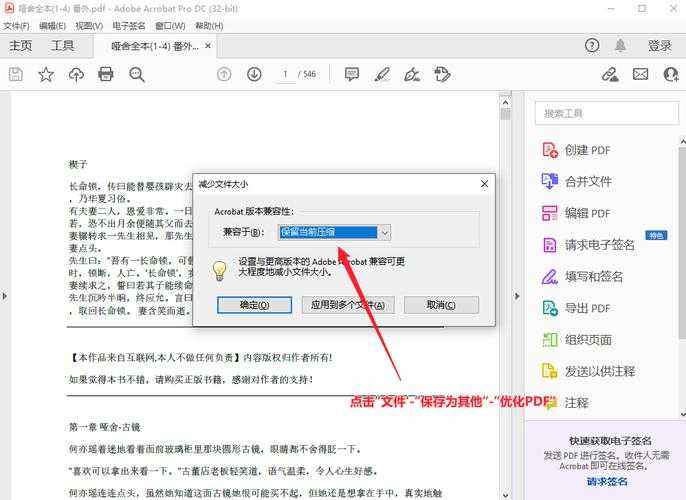
- 点击右上角"选项"按钮
- 取消勾选"优化PDF以减小文件大小"
- 在"文件大小"下拉框选择"保留现有"
这个方法最适合需要保持印刷级质量的PDF合并需求。上周帮出版社合并画册时,20个300dpi的高清PDF合并后,总大小1.2GB的文件完全没被压缩。
Windows用户的隐藏技巧
在Windows 10/11上,按住Shift右键点击PDF文件,选择"合并文件"会直接调用系统内置功能。虽然选项简单,但实测发现Windows自带的PDF合并默认不会压缩文件,适合快速处理日常文档。方法二:用Ghostscript命令行精准控制
技术流必备的终极方案
对于需要批量处理的技术人员,推荐这个开源方案:- 安装Ghostscript(建议用9.55版本)
- 打开命令提示符输入:
gswin64c -dNOPAUSE -dBATCH -sDEVICE=pdfwrite -dPDFSETTINGS=/default -sOutputFile=merged.pdf file1.pdf file2.pdf
关键参数说明:
- -dPDFSETTINGS=/default 保持原始质量
- -dCompatibilityLevel=1.7 兼容旧版阅读器
- -dAutoRotatePages=/None 禁止自动旋转
方法三:Python代码实现自动化合并
程序员最爱的可编程方案
用PyPDF2库写个脚本,适合需要集成到工作流的场景:from PyPDF2 import PdfMergermerger = PdfMerger()for pdf in ["file1.pdf", "file2.pdf"]:merger.append(pdf, import_bookmarks=False)merger.write("merged.pdf")merger.close()这个方法最大的优势是可以精确控制每个PDF的合并方式,还能保留书签、表单等特殊元素。我们团队就用这个方案开发了自动化投标文件生成系统。
避坑指南:5个常见错误
- 错误1:使用在线合并工具(90%会压缩)
- 错误2:导出时勾选了"优化PDF"选项
- 错误3:用截图方式"合并"PDF(画质灾难)
- 错误4:在手机APP上操作(压缩更激进)
- 错误5:合并后没有做质量检查
不同场景的最佳选择
| 使用场景 | 推荐方案 | 注意事项 |
|---|---|---|
| 日常办公文档 | Windows自带功能 | 检查是否保留表单字段 |
| 设计印刷文件 | Adobe Acrobat | 确认色彩配置 |
| 批量自动化处理 | Python脚本 | 处理异常文件 |
终极建议:先测试再量产
无论选择哪种PDF合并不压缩的方法,都建议先用小文件测试。有次我合并200页技术手册时,就因为字体嵌入问题导致整个下午白忙活。记住这个原则:重要的文件合并前,永远先做测试合并!如果这篇解决你PDF合并如何不压缩的难题,欢迎分享给经常处理PDF的同事~