爬虫Excel转PDF:数据处理工作流的终极效率提升方案
# 从爬虫数据到PDF报告:Excel自动化转换的实战指南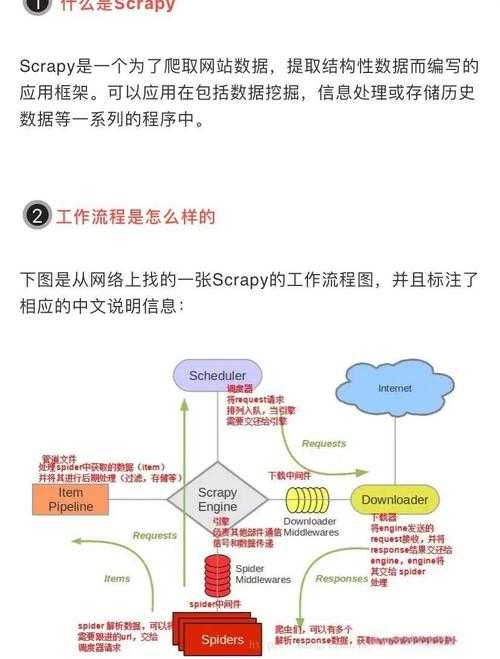
记得上周,我的一位做市场分析的朋友小王向我吐槽:他每天要处理几十个爬虫抓取的Excel文件,然后手动转换成PDF发给客户,经常加班到深夜。这让我意识到,很多人在**爬虫数据excel转pdf**这个环节上,还在用着石器时代的方法。
操作步骤:
1. 打开爬虫生成的Excel文件
2. 点击"文件" → "导出" → "创建PDF/XPS"
3. 调整页面设置和打印区域
4. 选择发布范围和质量选项
这种方法在window环境下表现稳定,特别是当你使用最新版本的Office时,转换质量相当不错。但缺点是批量处理效率低,无法实现完全自动化。
核心代码框架:
```pythonimport pandas as pdfrom win32com.client import Dispatchimport osdef excel_to_pdf(excel_path, pdf_path):excel_app = Dispatch('Excel.Application')excel_app.Visible = Falseworkbook = excel_app.Workbooks.Open(excel_path)workbook.ExportAsFixedFormat(0, pdf_path) # 0代表PDF格式workbook.Close()excel_app.Quit()```
这个方案的优势在于可以轻松集成到你的爬虫流程中,实现真正的端到端自动化。在window系统上,通过COM接口调用Excel,能够保证格式的完美保持。
这些工具在window服务器环境下运行稳定,支持:
- 统一字体和字号
- 设置合理的打印区域
- 处理超宽表格的分页
- 检查图表尺寸和位置
- 使用文件夹监控技术
- 实现并行处理
- 设置错误重试机制
- 添加进度通知功能
解决方案:确保系统字体库包含所需中文字体,在Excel中明确指定中文字体。
解决方案:调整图表DPI设置,建议设置为300dpi以上。
解决方案:采用分布式处理,或者使用专业的数据处理工具。
- 自动识别最佳页面布局
- 智能分页和内容重组
- 个性化内容适配
- 实时质量检测和优化
在window生态中,微软也在不断优化Office的转换引擎,未来的版本肯定会带来更好的体验。
记住,技术是为了提高效率服务的,不要为了技术而技术。我建议你从最简单的方案开始,逐步优化,最终形成适合自己的**爬虫数据excel转pdf**工作流。
如果你在实践过程中遇到任何问题,欢迎在评论区留言,我会尽力为大家解答。也欢迎大家分享自己的经验和技巧,让我们共同进步!
最后的小提示:在处理重要数据时,一定要做好备份,转换前最好先在小批量数据上测试效果。毕竟,数据安全永远是第一位的!
爬虫Excel转PDF:数据处理工作流的终极效率提升方案
为什么你需要关注爬虫数据到PDF的转换?
大家好,我是老张,一个在数据处理领域摸爬滚打十多年的技术博主。今天想和大家聊聊一个看似简单却暗藏玄机的话题——**爬虫excel转pdf**的完整工作流。你可能觉得这不过是文件格式转换的小事,但当我告诉你,合理优化这一流程能让你的工作效率提升300%,你还会觉得这是小事吗?记得上周,我的一位做市场分析的朋友小王向我吐槽:他每天要处理几十个爬虫抓取的Excel文件,然后手动转换成PDF发给客户,经常加班到深夜。这让我意识到,很多人在**爬虫数据excel转pdf**这个环节上,还在用着石器时代的方法。
爬虫Excel转PDF的三大核心挑战
数据格式保持的难题
爬虫抓取的数据往往格式不一,直接转换PDF经常出现排版错乱。特别是当你的Excel表格包含:- 合并单元格和复杂表头
- 图表和数据透视表
- 超长文本内容
- 特殊符号和公式
批量处理的效率瓶颈
单个文件转换简单,但面对几十上百个文件时,手动操作就变成了噩梦。我曾经统计过,一个熟练的办公人员完成100个文件的**批量爬虫excel转pdf**工作需要近3小时,而自动化方案只需5分钟。质量控制的隐形成本
每次转换后都需要人工检查,这个时间成本往往被低估。劣质的转换结果可能导致:- 客户对专业性的质疑
- 重要数据被截断或丢失
- 品牌形象受损
实战解决方案:从基础到高级
方案一:Office原生转换(适合初学者)
如果你只是偶尔需要处理几个文件,Windows系统自带的Office套件是最直接的选择。操作步骤:
1. 打开爬虫生成的Excel文件
2. 点击"文件" → "导出" → "创建PDF/XPS"
3. 调整页面设置和打印区域
4. 选择发布范围和质量选项
这种方法在window环境下表现稳定,特别是当你使用最新版本的Office时,转换质量相当不错。但缺点是批量处理效率低,无法实现完全自动化。
方案二:Python自动化脚本(技术推荐)
这是我个人最推荐的方案,特别适合需要频繁处理**爬虫数据excel转pdf**任务的技术人员。核心代码框架:
```pythonimport pandas as pdfrom win32com.client import Dispatchimport osdef excel_to_pdf(excel_path, pdf_path):excel_app = Dispatch('Excel.Application')excel_app.Visible = Falseworkbook = excel_app.Workbooks.Open(excel_path)workbook.ExportAsFixedFormat(0, pdf_path) # 0代表PDF格式workbook.Close()excel_app.Quit()```
这个方案的优势在于可以轻松集成到你的爬虫流程中,实现真正的端到端自动化。在window系统上,通过COM接口调用Excel,能够保证格式的完美保持。
方案三:专业工具链组合(企业级方案)
对于企业级应用,我建议使用专门的数据处理工具。比如Alteryx+Power BI的组合,或者基于云服务的解决方案。这些工具在window服务器环境下运行稳定,支持:
- 定时自动执行转换任务
- 多用户协同工作流
- 转换质量监控和报警
- 版本控制和审计追踪
高级技巧:提升转换质量的五个关键点
1. 预处理是关键
在**爬虫抓取数据excel转pdf**之前,一定要做好数据清洗和格式标准化:- 统一字体和字号
- 设置合理的打印区域
- 处理超宽表格的分页
- 检查图表尺寸和位置
2. 页面设置的艺术
很多人忽略了这个细节,但正确的页面设置能让PDF质量提升一个档次:| 参数 | 推荐值 | 说明 |
|---|---|---|
| 页面方向 | 根据表格宽度选择 | 宽表格用横向,长表格用纵向 |
| 页边距 | 1-1.5厘米 | 保证内容不被裁剪 |
| 缩放比例 | 适应页面宽度 | 避免用户需要手动缩放 |
3. 批量处理的最佳实践
当处理大量文件时,**批量爬虫excel转pdf**的效率优化至关重要:- 使用文件夹监控技术
- 实现并行处理
- 设置错误重试机制
- 添加进度通知功能
避坑指南:常见问题及解决方案
问题1:中文乱码
症状:PDF中的中文显示为方框或乱码解决方案:确保系统字体库包含所需中文字体,在Excel中明确指定中文字体。
问题2:图表失真
症状:转换后图表模糊或变形解决方案:调整图表DPI设置,建议设置为300dpi以上。
问题3:性能瓶颈
症状:大量文件转换时速度慢甚至崩溃解决方案:采用分布式处理,或者使用专业的数据处理工具。
未来展望:智能化转换的发展趋势
随着AI技术的发展,**爬虫excel转pdf**的流程正在变得更加智能化:- 自动识别最佳页面布局
- 智能分页和内容重组
- 个性化内容适配
- 实时质量检测和优化
在window生态中,微软也在不断优化Office的转换引擎,未来的版本肯定会带来更好的体验。
总结:打造属于你的高效工作流
通过今天的分享,相信你对**爬虫excel转pdf**有了更深入的理解。无论你是选择简单的Office原生方案,还是搭建复杂的自动化系统,关键在于找到最适合自己需求的解决方案。记住,技术是为了提高效率服务的,不要为了技术而技术。我建议你从最简单的方案开始,逐步优化,最终形成适合自己的**爬虫数据excel转pdf**工作流。
如果你在实践过程中遇到任何问题,欢迎在评论区留言,我会尽力为大家解答。也欢迎大家分享自己的经验和技巧,让我们共同进步!
最后的小提示:在处理重要数据时,一定要做好备份,转换前最好先在小批量数据上测试效果。毕竟,数据安全永远是第一位的!

