PDF表格数据抽取到Excel:从手动复制到智能转换的深度实践
PDF表格数据抽取到Excel:从手动复制到智能转换的深度实践
前言:为什么PDF转Excel总让你头疼?
作为一名常年与各种文档格式打交道的技术博主,我太理解大家在处理PDF表格时的痛苦了。上周我同事小王就遇到了一个典型场景:财务部门发来一份50页的供应商报价PDF,需要他把所有报价数据整理成Excel进行分析。结果他花了整整一下午手动复制粘贴,不仅效率低下,还差点因为格式错乱导致数据错误。这种“PDF转Excel”的需求在办公中太常见了,但很多人还在用最原始的方法。今天我就从技术角度,深度解析几种PDF表格数据抽取到Excel的实用方案,帮你彻底告别手动时代。
PDF表格的结构特性与转换难点
为什么PDF表格这么难处理?
要理解如何高效实现PDF转Excel,首先得明白PDF格式的设计初衷。PDF本质上是一种“只读”格式,它的核心目标是保证文档在任何设备上显示一致,而不是为了方便编辑。具体到表格数据,PDF中的表格可能呈现为:
- 真正的表格结构(有边框线)
- 仅通过文本对齐形成的视觉表格
- 扫描图片中的表格(完全无法直接编辑)
表格数据抽取的关键挑战
格式保持问题
当我们需要将PDF表格数据抽取到Excel时,最大的挑战是如何保持原始数据的结构和格式。简单的复制粘贴往往会导致:- 单元格合并信息丢失
- 文本换行位置错乱
- 数字格式(如货币、百分比)被破坏
- 表格边框线完全消失
批量处理效率
对于需要PDF表格数据抽取到Excel的多页文档,手动操作几乎是不现实的。这就是为什么我们需要寻找更智能的解决方案。四种PDF转Excel方法深度对比
方法一:手动复制粘贴(基础版)
虽然效率最低,但作为应急方案还是值得了解:- 在PDF阅读器中选中表格内容
- Ctrl+C复制,在Excel中Ctrl+V粘贴
- 手动调整格式和布局
方法二:Adobe Acrobat Pro(专业版)
作为PDF的“官方”解决方案,Acrobat Pro提供了较为可靠的表格导出功能:- 用Acrobat Pro打开PDF文件
- 选择“导出PDF”功能
- 选择“电子表格”作为输出格式
- 调整导出设置后确认
局限:需要付费软件,对扫描版PDF效果有限。
方法三:在线转换工具(便捷版)
对于偶尔需要PDF表格数据抽取到Excel的用户,在线工具是个不错的选择:- Smallpdf、iLovePDF等知名平台
- 直接上传文件,自动转换后下载
- 通常有免费额度限制
方法四:专业数据提取软件(高效版)
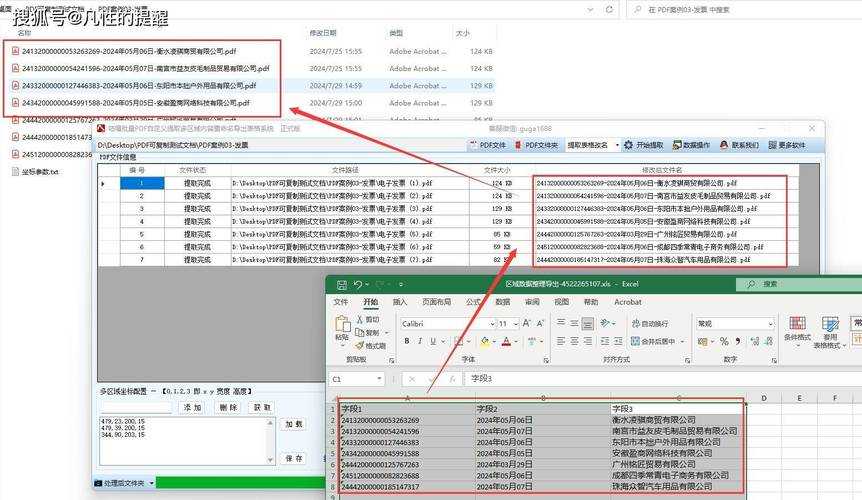
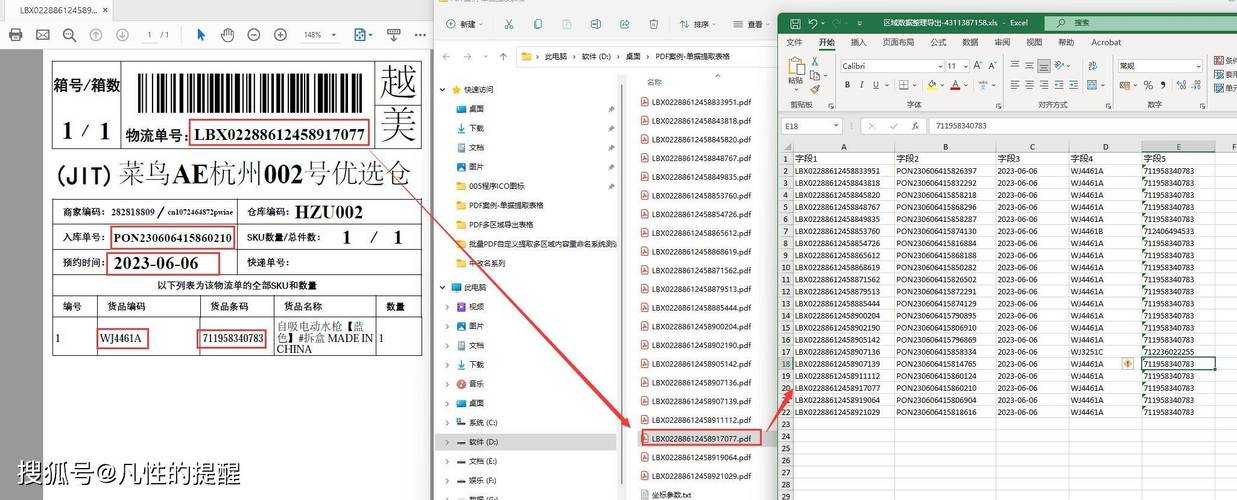
这是我个人最推荐的方案,特别是对于需要频繁进行PDF表格数据抽取到Excel的专业用户。在Windows平台上,有一款名为“Able2Extract”的软件表现尤为出色。这款软件在Windows系统上运行稳定,充分利用了Windows的图形处理能力,能够智能识别各种复杂表格结构。它的批量处理功能特别适合处理大量PDF文档,大大提升了PDF表格数据抽取到Excel的工作效率。
实战案例:复杂财务报表的智能转换
场景描述
最近我帮一个客户处理了一份年度财务报表PDF,这份文档具有以下特点:- 包含多个关联表格
- 有复杂的单元格合并
- 数字格式多样(货币、百分比等)
- 总计行和明细行的层级关系
转换步骤详解
第一步:软件选择与配置
我选择了在Windows 11系统上运行Able2Extract Professional版本。Windows系统的稳定性确保了长时间批量处理的可靠性,不会因为系统崩溃导致前功尽弃。软件安装后,需要根据具体需求调整识别设置:
- 设置表格识别敏感度
- 配置数字格式处理规则
- 定义多页表格的关联方式
第二步:批量处理与质量控制
通过软件的批量处理功能,一次性导入所有需要转换的PDF文件。在Windows任务管理器中可以监控转换进度,确保系统资源分配合理。转换完成后,必须进行质量检查:
- 核对数据完整性
- 检查格式准确性
- 验证公式计算正确性
第三步:后期优化技巧
即使是最高级的PDF转Excel工具,转换结果也可能需要微调。我总结了一些实用技巧:- 使用Excel的“文本分列”功能清理数据
- 设置条件格式突出异常值
- 创建数据验证规则确保后续输入质量
高级技巧:让PDF到Excel的转换更智能
利用OCR技术处理扫描文档
对于扫描版的PDF文档,普通的PDF表格数据抽取到Excel方法完全无效。这时候就需要OCR(光学字符识别)技术的帮助。在Windows平台上,ABBYY FineReader是这方面的佼佼者。它能够:
- 自动识别扫描文档中的文字
- 重建表格结构
- 保持原始格式和布局
自动化脚本的运用
对于需要定期处理相似结构PDF的专业用户,可以考虑使用Python等编程语言编写自动化脚本。结合PyPDF2、tabula-py等库,可以实现高度定制化的PDF表格数据抽取到Excel流程。避坑指南:常见问题与解决方案
转换后数据错位怎么办?
这是PDF转Excel过程中最常见的问题,通常是由于:- PDF中的表格边框不清晰
- 文本间距异常
- 特殊字符干扰
转换速度过慢的优化建议
处理大型PDF文档时,转换速度可能成为瓶颈。在Windows系统上,可以通过以下方式优化:- 关闭不必要的后台程序
- 增加虚拟内存大小
- 使用SSD硬盘提升读写速度
总结:选择最适合你的PDF转Excel方案
通过今天的深度探讨,相信你对“PDF转Excel”这个看似简单实则复杂的技术有了全新认识。无论是简单的复制粘贴,还是专业的软件解决方案,关键是找到适合自己需求的方法。对于Windows用户来说,系统平台的稳定性和丰富的软件生态为PDF表格数据抽取到Excel提供了有力支持。从个人使用经验来看,投资一款专业的转换软件往往能在长期工作中带来显著的时间回报。
记住,技术工具的价值不在于它有多先进,而在于它能否真正解决你的实际问题。希望今天的分享能帮助你在下次遇到PDF表格转换需求时,能够更加从容应对!
小贴士:如果你有特别的PDF转换需求或遇到棘手问题,欢迎在评论区留言,我会尽力为大家解答。