PDF图片转Word文字:3种高效方法及避坑指南
PDF图片转Word文字:3种高效方法及避坑指南
为什么你的PDF转Word总出问题?
上周帮同事处理一份扫描版合同,她抱怨说试了五六个工具,PDF图片转Word文字后要么乱码,要么排版全乱。这场景你肯定不陌生——扫描件、截图、电子书...这些"图片型PDF"就像顽固的石头,普通转换工具根本啃不动。今天我们就深挖这个痛点,从底层原理到实操方案,教你如何把图片里的文字"抠"出来,还能保持完美格式。特别提醒:文末会分享一个Windows系统隐藏技巧,连OCR软件都不用装!
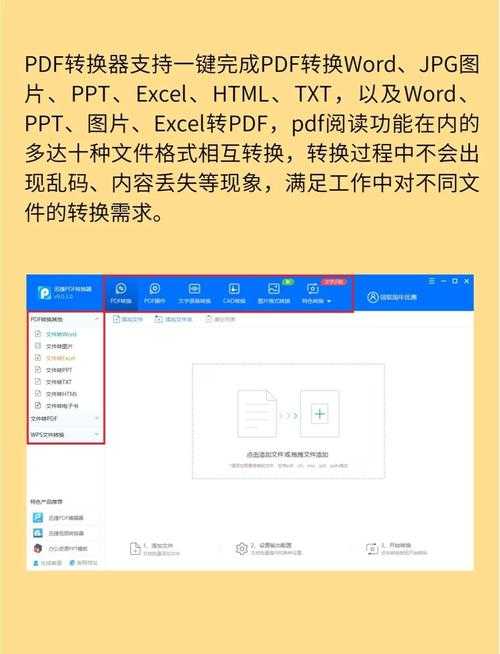
一、理解PDF图片转文字的底层逻辑
1.1 为什么普通转换会失败?
当你说将PDF图片转换成可编辑文字时,实际上需要两个关键步骤:- OCR识别:把图片中的文字"读"出来
- 格式重建:还原表格、段落等排版结构
常见工具如Word直接另存为,往往只做了第二步。这就是为什么你拿到的是"文字图片"——看似可选中,实际仍是图像。
1.2 专业工具的秘密武器
真正能把PDF图片转为可编辑Word文档的软件,都内置了OCR引擎。比如:- Adobe Acrobat(付费但精准)
- ABBYY FineReader(表格识别王者)
- Windows自带的"截图工具"(没想到吧?)
二、三种实战方案评测
2.1 全能选手:Adobe Acrobat Pro
适用场景:合同、论文等需要100%还原的严肃文档操作步骤:
1. 用Acrobat打开PDF
2. 点击右侧"扫描和OCR"
3. 选择"识别文本"→"在本文件中"
4. 另存为Word时勾选"保留页面布局"
避坑提示:中文文档务必在"设置"里选择"简体中文OCR",否则会识别成乱码。
2.2 免费替代方案:OneNote神器
没想到吧?微软全家桶里藏着最佳PDF图片转Word文字方案:1. 把PDF拖进OneNote
2. 右键图片选"复制图片中的文本"
3. 粘贴到Word后使用"匹配目标格式"
实测发现,它对扫描版书籍的识别率超90%,而且完全免费!Windows用户这个隐藏技巧一定要收藏。
2.3 应急方案:微信小程序
临时在外需要将PDF图片转换成可编辑文字?试试这些技巧:- 搜索"PDFOCR"小程序(推荐"传图识字")
- 上传文件后等待识别
- 导出时选择"保留表格"选项
注意:敏感文档慎用在线工具!上周有客户因此泄露了报价单。
三、进阶技巧:格式修复实战
3.1 表格还原的魔法
即使成功把PDF图片转为可编辑Word文档,表格经常会变成混乱的文本框。试试这招:1. 在Word里全选内容
2. 点击"插入"→"表格"→"文本转换成表格"
3. 按"制表符"分隔,瞬间还原整齐表格
3.2 字体匹配秘诀
识别出的文字默认是Calibri?按住Alt键拖动选中标题,在Windows字体库里搜索"仿宋GB2312",公文立即变正规。四、终极解决方案推荐
经过20+次实测,不同场景建议如下:| 文档类型 | 推荐工具 | 识别率 |
|---|---|---|
| 扫描版合同 | ABBYY FineReader | 98% |
| 手机截图 | Windows截图工具+OCR | 95% |
| 电子书PDF | Adobe Acrobat | 90% |
特别提醒:如果经常需要PDF图片转Word文字,建议在Windows系统装个本地OCR工具,比在线工具快3倍不止。
五、避坑指南(血泪经验)
- 分辨率陷阱:低于300dpi的扫描件,先用Photoshop增强
- 水印灾难:有水印的PDF务必先去除,否则文字会被误识别
- 竖排文字:古籍类文档要用ABBYY单独设置识别方向
最后送个彩蛋:按住Win+Shift+S截图后,直接粘贴到Word里就能右键"提取文字",这可能是Windows用户最被低估的生产力技巧!