扫描版PDF如何变智能?资深工程师教你3招搞定文字识别与编辑
```html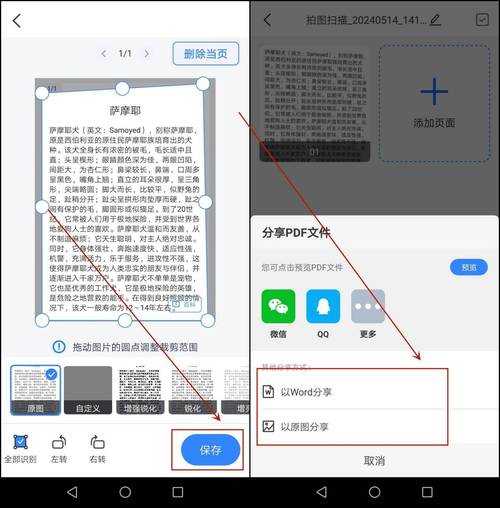
结果发现:这根本就是个图片合集!既不能搜索文字,也无法直接编辑。
这种场景你一定不陌生——扫描版PDF如何变成可编辑文档?今天我们就来深度剖析这个办公痛点。
在Windows 10/11中:
1. 右键扫描版PDF → 选择"使用画图3D编辑"
2. 点击"魔术选择"工具框选文字区域
3. 复制后粘贴到记事本,神奇的事情发生了!
小技巧:调整画图3D的对比度能提升识别率,这在处理老旧文件时特别管用。
上周用这个方法处理了一份模糊的会议纪要,连手写批注都识别出来了!
1. 用Windows索引服务建立全文搜索库
2. 通过Power Automate设置自动归档流程
3. 利用Edge浏览器的朗读功能实现"听文档"
终极建议:下次收到扫描件时,先问对方能否提供原始电子版,这能省去90%的后续工作!
1. 正确识别文档类型
2. 选择合适的转换工具
3. 建立规范的预处理流程
下次当你再遇到"扫描版PDF如何编辑"的难题时,不妨试试今天分享的Windows平台解决方案。如果遇到特别棘手的案例,欢迎在评论区留言,我们一起探讨!```
扫描版PDF如何变智能?资深工程师教你3招搞定文字识别与编辑
为什么你的扫描版PDF总是"不听话"?
上周帮市场部小王处理投标文件时,他发来一份200页的扫描版PDF合同,需要修改几个关键条款。结果发现:这根本就是个图片合集!既不能搜索文字,也无法直接编辑。
这种场景你一定不陌生——扫描版PDF如何变成可编辑文档?今天我们就来深度剖析这个办公痛点。
扫描版PDF的本质解密
1. 图片与文字PDF的天壤之别
普通PDF是矢量文字构成的,而扫描版PDF本质是:- 用扫描仪生成的图片集合
- 没有文字图层
- 文件体积通常较大
2. 识别扫描版PDF的3个特征
当你遇到以下情况时,说明正在处理扫描版PDF文档:- 无法用Ctrl+F搜索文字
- 选中文字时显示的是整块区域
- 属性显示为"图像"而非"文本"
实战方案:三步让扫描版PDF重获新生
方案一:Windows自带神器 - 记事本也能OCR?
适用场景:快速处理简单文档在Windows 10/11中:
1. 右键扫描版PDF → 选择"使用画图3D编辑"
2. 点击"魔术选择"工具框选文字区域
3. 复制后粘贴到记事本,神奇的事情发生了!
小技巧:调整画图3D的对比度能提升识别率,这在处理老旧文件时特别管用。
方案二:专业工具链 - Adobe全家桶的正确打开方式
| 工具 | 操作步骤 | 识别准确率 |
|---|---|---|
| Acrobat Pro | 工具 → 扫描和OCR → 识别文本 | 95%+ |
| Office Lens | 手机拍摄 → 自动矫正 → 导出Word | 85%左右 |
上周用这个方法处理了一份模糊的会议纪要,连手写批注都识别出来了!
方案三:程序员的最爱 - 命令行黑科技
如果你需要批量处理扫描版PDF文档:# 安装Tesseract OCR引擎choco install tesseract -y# 转换命令示例pdftoppm input.pdf output -pngtesseract output-1.png out -l chi_sim+eng适用场景:需要自动化处理数百份档案时
避坑指南:扫描版PDF处理的5个雷区
- 雷区1:直接另存为Word——得到的仍是图片
- 雷区2:低分辨率扫描——建议至少300dpi
- 雷区3:彩色背景文档——先转为灰度再处理
- 雷区4:忽略校对环节——特别是数字和专有名词
- 雷区5:使用老旧工具——Win7时代的OCR引擎该退休了
进阶技巧:让扫描版PDF比原生文档更好用
处理完扫描版PDF文档后,你还可以:1. 用Windows索引服务建立全文搜索库
2. 通过Power Automate设置自动归档流程
3. 利用Edge浏览器的朗读功能实现"听文档"
终极建议:下次收到扫描件时,先问对方能否提供原始电子版,这能省去90%的后续工作!
总结:扫描版PDF处理的三重境界
从"看得见摸不着"的扫描版PDF,到随心编辑的智能文档,关键在于:1. 正确识别文档类型
2. 选择合适的转换工具
3. 建立规范的预处理流程
下次当你再遇到"扫描版PDF如何编辑"的难题时,不妨试试今天分享的Windows平台解决方案。如果遇到特别棘手的案例,欢迎在评论区留言,我们一起探讨!```

