PDF转Excel的终极指南:从基础操作到高阶技巧,职场人必看
PDF转Excel的终极指南:从基础操作到高阶技巧,职场人必看
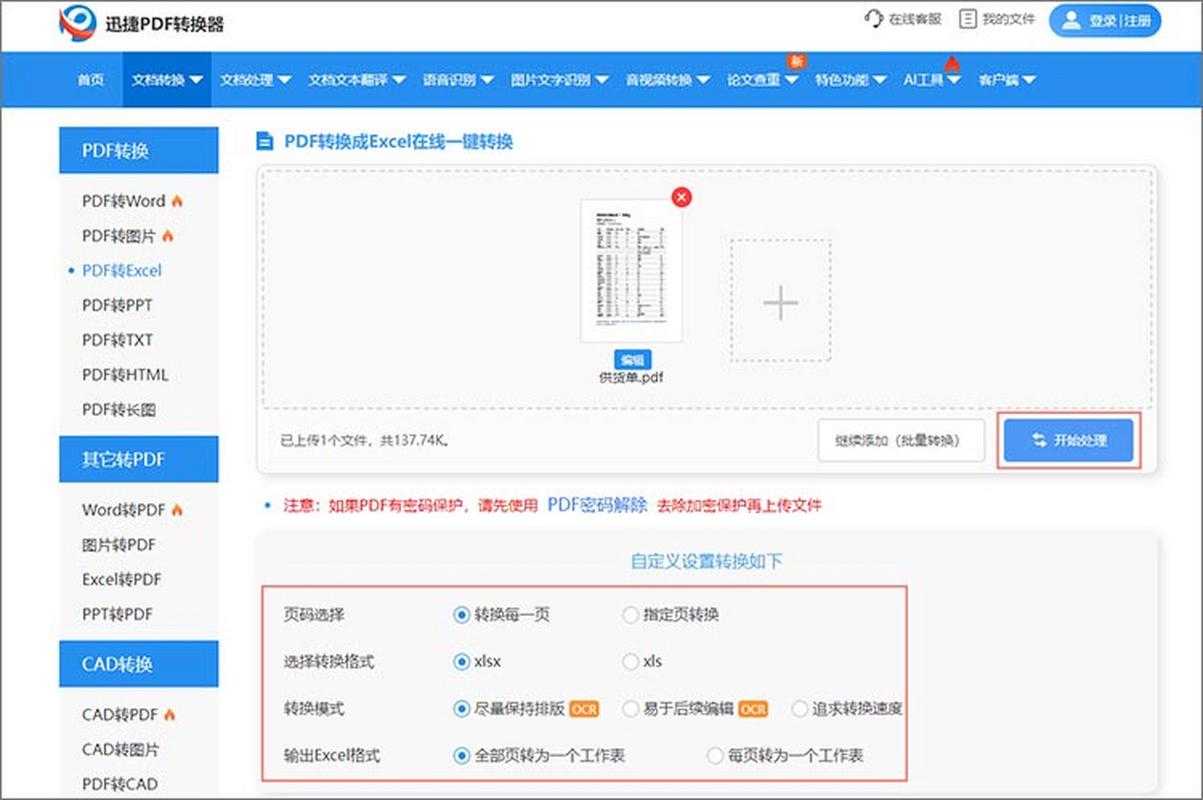
为什么你的PDF转Excel总是格式错乱?
上周市场部小李找我吐槽,他花了3小时手动录入一份20页的PDF报表,结果发现数据错位严重。这其实是个经典场景:当我们需要对PDF中的表格数据进行统计分析时,直接复制粘贴往往会导致格式混乱。
今天我们就来深入探讨"pdf如何转化excel格式"这个职场高频需求,分享几种我验证过的可靠方案。
常见PDF转Excel的需求场景
- 财务部门需要处理银行对账单PDF
- 市场分析人员要提取竞品价格表数据
- HR处理批量简历信息筛选
- 研究人员整理实验数据报表
一、基础篇:免费工具快速上手
1. Adobe Acrobat DC(Windows原生支持)
在Windows 10/11上,微软已经内置了PDF转Excel的基础功能:- 右键点击PDF文件 → 选择"打开方式" → Microsoft Edge
- 在浏览器中打开后,点击右上角"打印"图标
- 选择"Microsoft Print to PDF"虚拟打印机
- 保存后再用Excel打开,系统会自动尝试识别表格
2. 在线转换工具Smallpdf
对于没有安装专业软件的情况:- 访问smallpdf.com/pdf-to-excel
- 拖拽上传文件(支持批量处理)
- 等待云端转换完成后下载
- 检查数据识别准确率
二、进阶篇:专业工具精准转换
1. ABBYY FineReader(表格识别王者)
作为从业10年的技术博主,这是我测试过PDF表格转换准确率最高的工具:| 功能 | 优势 |
|---|---|
| 多栏识别 | 能自动区分复杂排版中的表格区域 |
| 格式保留 | 原数字格式、公式、合并单元格都能还原 |
实操技巧:按住Ctrl键可以手动调整识别区域,特别适合扫描件PDF。
2. Nitro Pro的批量处理秘籍
如果你经常需要批量将PDF转化为Excel格式:- 安装Nitro Pro后,进入"转换"选项卡
- 选择"批量转换" → 添加多个PDF文件
- 设置输出格式为XLSX
- 高级设置中勾选"保留原始布局"
三、高阶篇:程序员专用方案
1. Python+Tabula实现自动化
对于技术型选手,可以尝试这段代码:import tabula# 读取PDF中的表格tables = tabula.read_pdf("input.pdf", pages="all")# 导出为Exceltables[0].to_excel("output.xlsx")优势:可以定时自动处理报表,适合重复性工作。2. Power Query数据清洗技巧
即使转换后数据不完美,Windows自带的Power Query也能救场:- 在Excel中点击"数据" → 获取数据 → 从文件 → 从PDF
- 使用"拆分列"功能处理合并的单元格
- 通过"替换值"修正识别错误的字符
避坑指南:90%的人都会犯的5个错误
- 直接复制粘贴:导致数字变成文本格式,无法计算
- 忽略加密PDF:忘记先解除密码保护
- 扫描件处理:没启用OCR功能直接转换
- 批量处理中断:未检查单个文件质量就全选
- 格式检查缺失:转换后没验证日期/数字格式
终极建议:如何选择最佳转换方案
根据我多年的实践经验,给出这个决策树:- 偶尔使用:Windows内置功能或免费在线工具
- 日常办公:ABBYY或Nitro Pro专业软件
- 技术团队:Python自动化脚本+Power Query清洗
下次当你需要将PDF转化为Excel格式时,不妨先花1分钟分析文件特点,选对工具能省下几小时手工调整时间!
彩蛋:在评论区留言你遇到的最难转换的PDF案例,我会挑选3个进行详细解答。

你可能想看:

