PDF文档OCR识别:从安装到实战的完整指南
PDF文档OCR识别:从安装到实战的完整指南
为什么你的PDF需要OCR识别?
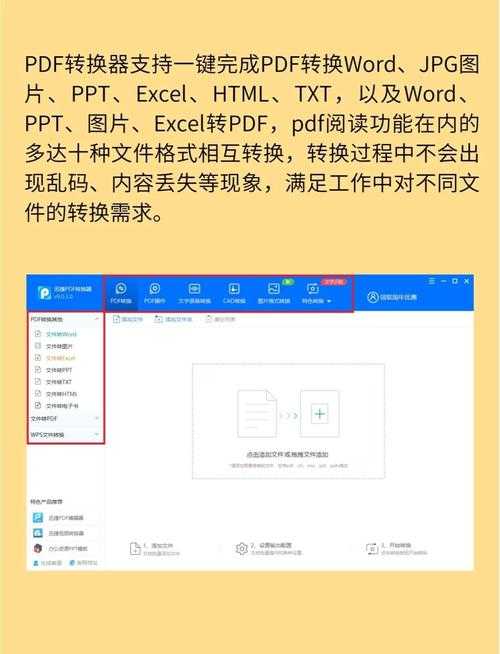
上周有个读者找我吐槽,说收到客户发来的扫描版合同PDF,想修改几个条款却发现文字无法选中——这就是典型的非可搜索PDF。其实解决这个问题很简单,学会pdf的ocr如何安装就能让扫描件秒变可编辑文档。OCR(光学字符识别)技术能帮你把图片中的文字转换成可编辑文本。今天我们就来聊聊如何在Windows系统上实现PDF的OCR识别,我会分享几种不同场景下的解决方案。
一、Windows自带OCR工具:最省心的选择
1. 使用Windows 10/11内置功能
很多人不知道,其实Windows系统自带OCR功能。在开始菜单搜索"Windows传真和扫描",这个工具就能帮你完成简单的OCR识别。操作步骤:
- 打开"Windows传真和扫描"应用
- 点击"新扫描",放入你的纸质文档
- 在设置中选择"另存为可搜索PDF"
- 扫描完成后会自动生成可搜索的PDF
适用场景:
- 临时需要处理少量文档
- 不想安装额外软件
- 对识别精度要求不高
二、专业PDF OCR软件推荐
1. Adobe Acrobat Pro DC:行业标杆
说到pdf文档ocr识别工具,Adobe绝对是首选。虽然要付费,但识别精度和功能完整性无人能及。安装步骤:
- 从Adobe官网下载Acrobat Pro DC试用版
- 安装时记得勾选"OCR组件"
- 打开PDF后点击"增强扫描"→"识别文本"
- 选择识别语言和输出格式
小技巧:按住Ctrl+D可以快速打开文档属性,查看OCR识别状态。
2. ABBYY FineReader:多语言识别专家
如果你经常处理多语言pdf文档ocr识别,这款俄罗斯开发的软件值得尝试。它对中文、日文等亚洲语言的支持特别好。安装注意事项:
- 安装包较大(约1GB),建议预留足够空间
- 首次运行会自动下载语言包
- 在"选项"中可以设置识别精度等级
三、免费OCR解决方案
1. 在线OCR工具
对于偶尔需要pdf转ocr的用户,在线工具更方便。比如iLovePDF、Smallpdf都提供免费额度。使用建议:
- 敏感文档不要上传到第三方服务器
- 检查网站的隐私政策
- 免费版通常有页数限制
2. Tesseract OCR:开源神器
技术爱好者可以试试这个谷歌开源的OCR引擎。虽然安装稍复杂,但完全免费且可定制。Windows安装指南:
- 从GitHub下载最新Windows安装包
- 安装时勾选"添加到系统PATH"
- 通过命令行调用:tesseract 输入文件 输出文件 -l chi_sim
- 中文识别需要额外下载语言包
四、实战技巧与避坑指南
1. 提高OCR识别率的5个秘诀
- 扫描分辨率至少300dpi
- 确保文档平整无阴影
- 复杂版式先做预处理
- 选择正确的语言包
- 手写体需要特殊训练
2. 常见问题解决
Q:为什么我的pdf文档ocr识别后乱码?A:通常是语言设置错误。中文文档要选择"简体中文"或"chi_sim"参数。
Q:表格识别不准确怎么办?
A:专业工具如ABBYY有专门的表格识别模式,或者先用Excel处理再导入PDF。
五、不同场景下的最佳选择
| 使用场景 | 推荐方案 |
|---|---|
| 偶尔使用 | Windows自带工具/在线OCR |
| 日常办公 | Adobe Acrobat标准版 |
| 多语言处理 | ABBYY FineReader |
| 批量处理 | Tesseract+自动化脚本 |
写在最后
掌握pdf的ocr如何安装只是第一步,关键是根据你的实际需求选择工具。我建议先从Windows自带功能试起,再逐步尝试专业工具。记住,好的OCR工作流程=合适的工具+正确的预处理+仔细的校对。如果你在安装或使用过程中遇到问题,欢迎在评论区留言。下期我会分享如何用Python自动化OCR处理,敬请期待!