PDF图片提取终极指南:5种方法帮你轻松搞定,最后一种90%的人都不知道
PDF图片提取终极指南:5种方法帮你轻松搞定,最后一种90%的人都不知道
为什么你总是为PDF里的图片发愁?
上周帮同事处理投标文件时,发现他花了半小时在截图PDF里的产品图——这可能是职场人最常踩的效率陷阱。其实PDF保存图片根本不需要截图工具,今天我就分享5种亲测有效的解决方案,特别是最后那个隐藏技巧,连十年老会计看完都直呼内行。
▌先搞懂PDF图片的两种存在形式
在讲解如何从PDF导出高清图片前,必须明白:- 嵌入式图片:直接存储在PDF中的原始图像文件
- 矢量图形:由路径和公式组成的可缩放图形
方法一:Windows自带打印大法(零成本方案)
适用场景:临时需要提取少量图片
- 用Edge浏览器打开PDF文件
- 右键选择"打印"
- 打印机选择"Microsoft Print to PDF"
- 在"页面"设置里勾选"打印标记"
- 保存后直接用画图工具裁剪
坑点预警:复杂版式可能错位,建议配合Snipaste截图工具使用
方法二:Adobe Acrobat专业操作(原厂方案)
职场精英都在用的标准流程
去年给市场部培训时,他们最惊讶的就是这个导出PDF内嵌图片的功能:- 用Acrobat DC打开PDF
- 右侧工具栏点击"导出PDF"
- 选择"图像→JPEG/PNG"
- 设置输出质量(建议300dpi以上)
| 格式 | 适用场景 |
|---|---|
| JPEG | 照片类内容 |
| PNG | 带透明底的LOGO |
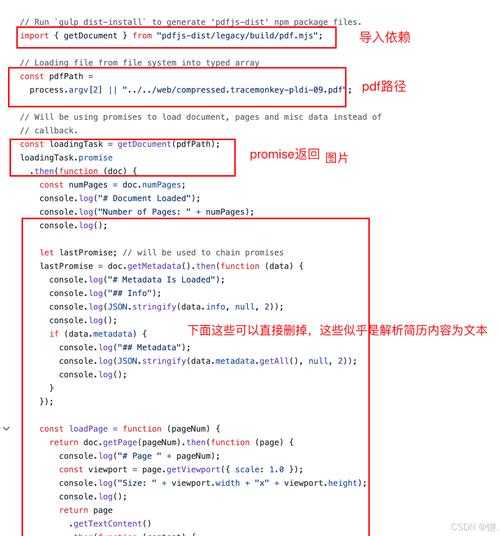
方法三:Python自动化脚本(极客专属)
需要批量处理200+产品手册时,我写了这个脚本:import PyPDF2pdf_file = open('catalog.pdf', 'rb')pdf_reader = PyPDF2.PdfFileReader(pdf_file)for page in pdf_reader.pages:for image in page.images:with open(image.name, 'wb') as f:f.write(image.data)技术要点:PyPDF2库会自动识别PDF文档中的图片资源,适合程序员批量处理。方法四:Smallpdf在线工具(跨平台救星)
当你在客户公司用Mac临时需要将PDF转存为图片时:- 访问smallpdf.com
- 选择"PDF转JPG"功能
- 拖拽文件上传(支持批量)
- 下载ZIP压缩包
方法五:文件后缀暴力破解(隐藏技巧)
90%用户不知道的底层原理
其实PDF本质是压缩包,试试这个骚操作:- 将test.pdf重命名为test.zip
- 解压后进入/images目录
- 所有原始图片都在这里!
避坑指南:这些雷区千万别踩
血泪教训总结的注意事项
1. 分辨率陷阱:很多工具默认输出96dpi,打印会模糊,建议:
- 印刷品设置300dpi以上
- 电子屏使用150dpi即可
去年法务部特别提醒:
- 商用图片务必确认授权
- 学术用途注意引用规范
终极建议:根据场景选方案
最后送大家一张决策流程图:| 需求场景 | 推荐方案 |
|---|---|
| 临时应急 | Windows打印导出 |
| 专业设计 | Acrobat原厂工具 |
| 批量处理 | Python脚本 |