PDF文本选择困境破解:从基础操作到高阶技巧全解析
PDF文本选择困境破解:从基础操作到高阶技巧全解析
为什么你的PDF总是选不中?
上周帮同事处理合同扫描件时,发现她花了半小时手动输入PDF里的表格数据——这场景你一定不陌生。实际上,如何选中PDF中的内容是数字办公中最容易被低估的技能之一。今天我们就深入探讨这个看似简单却暗藏玄机的操作。PDF选择的本质差异
首先要明白,PDF文档能否被选中取决于它的生成方式:- 文本型PDF:由Word/PPT等直接导出,文字可选中
- 图像型PDF:扫描件或截图生成,文字本质是图片
- 混合型PDF:部分文字可选中,部分为图像
基础篇:常规PDF文本选择技巧
Windows平台的标准操作
在Windows系统自带的Edge浏览器中打开PDF时(是的,它比很多专业工具更高效):- 按住左键拖动选择文本
- 三击段落可快速全选
- Ctrl+A全选后,右键"复制"保持格式
那些被忽略的右键菜单
在Adobe Reader中右键时:- "选择工具"可切换文本/图像选择模式
- "拍快照"能捕获不可选的图像区域
- "高亮选定内容"自动创建可检索标记
进阶篇:处理"顽固"PDF的5种武器
当文字就是选不中时
上周市场部发来的产品手册就是典型案例——看似文字实际是图片。这时如何选中PDF中的隐藏文字?试试这些方案:| 工具 | 操作步骤 | 适用场景 |
|---|---|---|
| Windows OCR | 右键PDF→"使用OCR识别文本" | 清晰扫描件 |
| Adobe Acrobat Pro | 工具→识别文本→在本文件 | 复杂版式 |
| 在线转换工具 | 上传→转换为Word→反向生成PDF | 临时应急 |
程序员偏爱的命令行方案
如果你经常需要批量处理PDF文档的选择问题,可以试试pdftotext工具:pdftotext -layout input.pdf output.txt这个开源工具能保留原始排版,特别适合处理技术文档。
职场实战:三个典型场景解决方案
场景1:合同关键条款提取
法务同事教我的妙招:用Windows版Foxit Reader的"选择→导出为Excel",自动将条款表格转为可编辑数据。场景2:学术论文参考文献抓取
遇到参考文献列表时,试试Zotero的"抓取PDF元数据"功能,比手动选择效率提升10倍不止。场景3:扫描版图书文字获取
去年整理古籍资料时发现,如何选中PDF中的古籍文字需要特殊处理:- 先用Photoshop调整对比度
- ABBYY FineReader设置"古籍"识别模式
- 最后用Calibre生成可检索EPUB
避坑指南:90%的人都会犯的3个错误
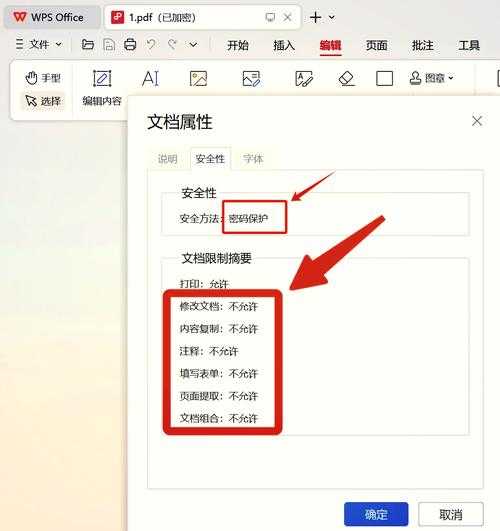
- 忽略PDF安全设置:右键查看文档属性→安全,确认没有内容复制限制
- 过度依赖OCR:手写体识别准确率通常低于40%,需要人工校对
- 格式丢失问题:复制到Word时选择"保留源格式",否则会丢失表格样式
终极建议:建立你的PDF处理工作流
根据文档类型建立自动化流程:- 日常办公文档:Windows资源管理器右键→"转换为可搜索PDF"
- 批量处理:用PowerShell调用Adobe SDK自动识别
- 敏感文件:在虚拟机中处理,避免OCR工具上传云端


