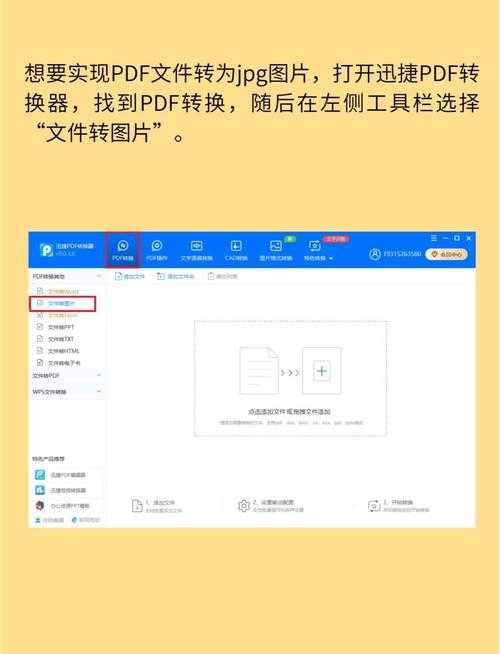
PDF文字提取的终极指南:从基础操作到高阶技巧全解析
PDF文字提取的终极指南:从基础操作到高阶技巧全解析
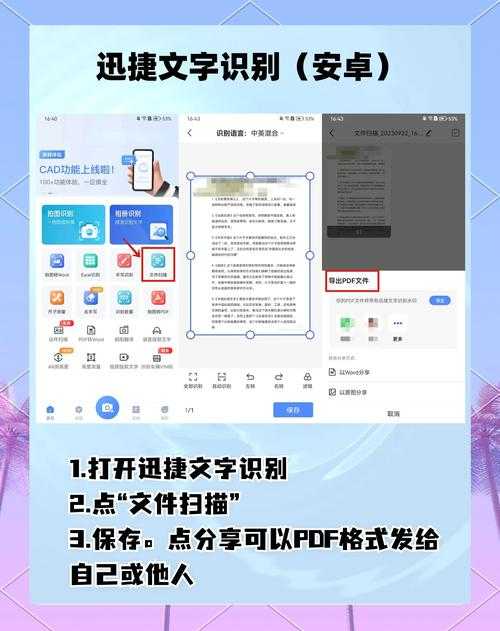
为什么你的PDF文字提取总是不顺利?
上周我帮同事处理一份扫描版合同,他折腾了半天都没法复制文字,最后发现原来是个图片型PDF...相信你也遇到过类似困扰。今天我们就来深度剖析pdf如何读取文字的各种方法,让你彻底掌握这门办公必备技能。PDF文字提取的三种核心场景
1. 可选中文字的常规PDF
这类PDF就像Word文档,文字可以直接选中复制。但很多人不知道的是:- Adobe Reader的选择工具其实有智能识别段落功能
- 在Windows系统下,Edge浏览器打开PDF后可以直接全选复制
- WPS Office的PDF转Word功能保留格式最完整
2. 扫描件/图片型PDF
这类是最让人头疼的,我常用的解决方案是:- 使用Windows自带的画图3D工具另存为高质量JPG
- 通过OneNote的图片转文字功能进行识别
- 或者直接用专业的ABBYY FineReader(准确率高达98%)
3. 加密保护的PDF文档
上周有个读者问我:"为什么我的PDF复制出来全是乱码?"检查后发现是权限限制。这种情况可以尝试:- 用Chrome浏览器打开后打印为PDF(会解除部分限制)
- 使用Smallpdf的解密工具在线处理
- 向文档所有者申请编辑权限(最合规的做法)
Windows用户的专属技巧
1. 右键菜单的隐藏功能
在Windows 11上,对着PDF文件右键→打开方式→选择其他应用,你会发现:| 应用 | 优势 |
|---|---|
| Edge浏览器 | 加载最快,支持朗读 |
| Word 2019+ | 直接编辑PDF内容 |
2. 命令行的魔法
按Win+R输入cmd,试试这个命令:pdftotext -layout input.pdf output.txt(需要先安装Xpdf工具包)这个技巧特别适合批量处理大量PDF文件。
高级玩家的必备工具
1. Python自动化方案
用PyPDF2库三行代码就能搞定:import PyPDF2reader = PyPDF2.PdfReader("example.pdf")print(reader.pages[0].extract_text())2. 云端解决方案对比
- Google Drive:免费但识别精度一般
- Microsoft Lens:Office 365用户首选
- 百度OCR:中文识别效果最佳
避坑指南:90%的人都会犯的错
- 直接截图粘贴到微信里识别(分辨率损失严重)
- 用手机拍照转换(透视变形影响准确率)
- 忽略PDF的文字编码问题(特别是日韩语文档)
终极建议:根据场景选择最佳方案
最后送你一个决策流程图:1. 能直接选中文字吗?→复制粘贴
2. 是扫描件吗?→用Windows自带的OCR或专业工具
3. 有加密保护?→先解除限制或联系文档所有者
记住,pdf如何读取文字这个问题没有万能解,关键是要理解文档类型和你的具体需求。下次遇到PDF提取难题时,不妨先花30秒分析文档特性,反而能节省大量时间!
(悄悄说:我电脑里常年备着Portable版的Adobe Acrobat和ABBYY,关键时刻真的能救命)