深度解析:如何高效阅读拉康PDF的5个关键技巧
深度解析:如何高效阅读拉康PDF的5个关键技巧
为什么你总是读不懂拉康的PDF?
作为一位长期与数字文档打交道的技术博主,我见过太多人对着拉康的PDF抓耳挠腮。上周就遇到个案例:某高校研究生小张,为了准备毕业论文,下载了十几篇拉康理论的原著PDF,结果在文献堆里越读越迷糊...
问题不在你,而在方法——今天我们就来聊聊如何用技术思维破解这个难题。
PDF阅读的认知陷阱
误区1:线性阅读的惯性思维
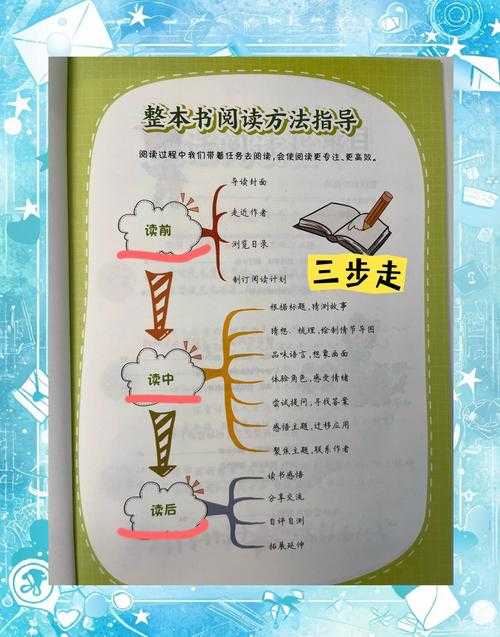
拉康的文本就像他的镜像理论一样,需要非线性阅读。- 先快速浏览目录结构(如果有的话)
- 用搜索功能定位关键词
- 重点标注反复出现的概念群
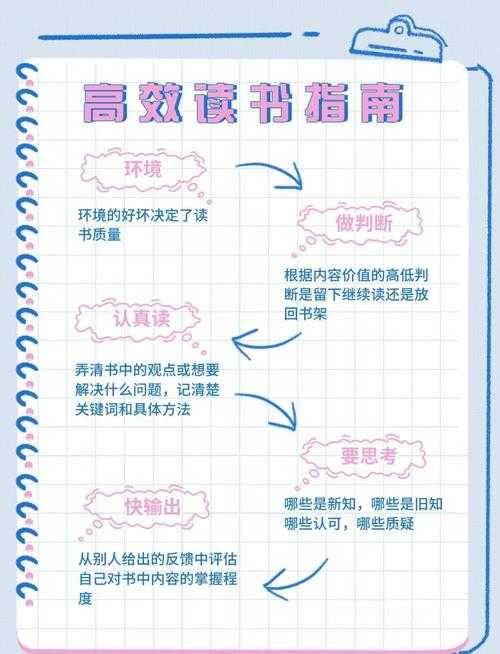
误区2:被动接受式阅读
在Windows系统上,我推荐使用Edge浏览器的PDF功能:- 右键点击PDF选择"在Microsoft Edge中打开"
- 使用内置的荧光笔和批注工具
- 通过"查找"功能(Ctrl+F)快速定位术语
专业工具链配置
基础装备:双屏工作法
左边屏幕放拉康PDF原文,右边开个思维导图工具(推荐XMind)。Windows 11的Snap Layouts功能简直是为此而生:
| 快捷键 | 功能 |
|---|---|
| Win+←/→ | 快速分屏 |
| Win+Tab | 创建虚拟桌面 |
进阶技巧:语义网络构建
当你在阅读拉康PDF时遇到"能指链"这类概念:- 用Zotero建立概念库
- 给每个术语添加自定义标签
- 通过笔记链接功能建立概念关联
阅读拉康PDF的实战步骤
第一步:元数据分析
用Adobe Acrobat查看文档属性(Ctrl+D),特别注意:- 创建日期判断版本
- 作者信息确认来源
- 关键词字段快速把握主题
第二步:结构化批注
我开发了一套颜色编码系统:| 颜色 | 用途 |
|---|---|
| 黄色 | 核心论点 |
| 蓝色 | 概念定义 |
| 绿色 | 疑问点 |
避坑指南
字体乱码解决方案
遇到PDF显示异常时:- 用Windows自带的字体查看器检查缺失字体
- 尝试用Foxit Reader等第三方工具打开
- 终极方案:打印为新的PDF
跨设备同步技巧
推荐使用OneDrive同步批注:- 设置自动保存到云端
- 通过版本历史找回误删内容
- 在手机端使用Office Lens拍摄纸质书对比
终极心法:建立你的拉康知识图谱
经过3个月的实践,我总结出这套方法:- 每周精读1-2篇核心PDF
- 用Notion建立概念数据库
- 定期绘制理论演进时间轴
- 参加线上读书会验证理解