文献管理终极指南:如何高效保存PDF文献并建立知识体系
文献管理终极指南:如何高效保存PDF文献并建立知识体系
为什么你的文献总是杂乱无章?
作为科研狗的你,是不是经常遇到这种情况:明明下载了几百篇文献PDF,要用时却死活找不到;
电脑里充斥着"论文1.pdf"、"最终版.pdf"、"最终版2.pdf"这类毫无意义的文件名;
重复下载同一篇文献却浑然不知...
今天我们就来聊聊如何保存文献PDF这个看似简单却暗藏玄机的话题。相信我,看完这篇,你的文献管理效率至少提升300%!
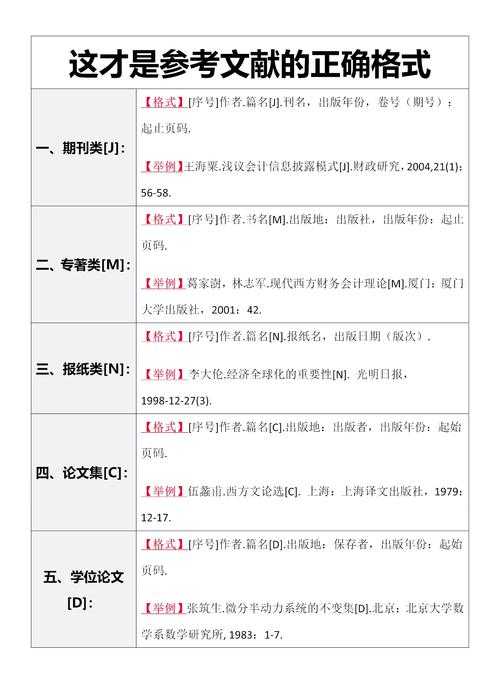
文献保存的三大核心原则
1. 标准化命名:告别"新建文件夹"地狱
我见过最离谱的案例是某博士生电脑里有17个"新建文件夹",每个里面都塞满了未命名的PDF。正确的文献PDF保存方式应该遵循这个公式:
- 作者_年份_标题关键词.pdf(例如:Smith_2020_AIinHealthcare.pdf)
- 期刊缩写+卷期页码(适合已发表论文)
- 项目编号+文献类型(适合企业研发场景)
Windows系统有个隐藏技巧:选中多个PDF后右键"重命名",输入"文献(",系统会自动补全"文献(1).pdf"的序列,比手动命名快10倍!
2. 结构化存储:建立你的数字图书馆
保存文献PDF文件不是终点,建立可检索的知识体系才是关键。推荐三级目录结构:- 一级目录:研究领域(如"人工智能")
- 二级目录:细分方向(如"计算机视觉")
- 三级目录:具体技术(如"目标检测")
Windows的库功能在这里大显身手:
右键新建库→命名为"文献库"→添加不同学科的文件夹,
这样无需移动物理文件,就能实现跨目录检索,特别适合多学科交叉研究。
3. 双重备份:数据安全的最后防线
我有个朋友(真的不是我)因为硬盘损坏,丢了三年积累的文献,现在还在心理治疗...保存重要文献PDF必须遵循3-2-1原则:
- 3份拷贝:原始+本地备份+云端
- 2种介质:硬盘+网盘
- 1份离线:冷存储(如蓝光刻录)
Windows用户可以用文件历史记录功能:
设置→更新和安全→备份→添加驱动器,系统会自动每小时备份文献文件夹。
进阶技巧:从保存到知识管理
文献元数据:隐藏在PDF里的宝藏
90%的人不知道,正确保存文献PDF应该先完善元数据:| 字段 | 必填内容 | 修改工具 |
|---|---|---|
| 标题 | 完整文献标题 | Adobe Acrobat |
| 作者 | 所有作者姓名 | Windows属性面板 |
| 关键词 | 3-5个核心词 | 专业PDF编辑器 |
小技巧:在Windows资源管理器右键PDF→属性→详细信息,可以直接编辑部分元数据,不用打开专业软件。
OCR识别:扫描件变可检索文本
老文献扫描件是知识管理的黑洞,试试这个方案:- 用Windows自带的"照片"应用打开扫描PDF
- Ctrl+A全选→右键"复制文本"
- 粘贴到记事本检查识别准确率
- 用Xodo等免费工具嵌入OCR文本层
这样处理后,保存的文献PDF文件就变成可全文检索的智能文档了。
避坑指南:文献管理常见误区
误区1:把所有文献堆在桌面
桌面就像你家的玄关——临时放东西可以,长期存储绝对灾难。建议在Windows中:
右键桌面→查看→取消勾选"将图标与网格对齐",
然后按住Ctrl+鼠标滚轮缩小图标,你会看到那些被遗忘的文献原来有这么多!
误区2:过度依赖文件夹分类
分类太细反而增加检索难度。我的经验是:保存文献PDF时先用粗粒度分类,
配合Everything等工具实现秒级搜索,
比翻十层文件夹高效得多。
误区3:忽视版本控制
文献的预印本、会议版、期刊版可能大不相同。推荐命名规则:
- v1:初稿
- v2:修改稿
- final:最终版
- pub:发表版
终极解决方案:专业工具组合拳
对于文献大户,我推荐这个黄金组合:- Zotero:自动抓取元数据+生成引用
- Adobe Acrobat:批量处理PDF元数据
- OneDrive:实时同步+版本历史
- Everything:本地秒搜
这套方案在Windows平台运行最流畅,特别是配合WSL使用,连Linux下的文献都能统一管理。
行动建议:从今天开始改变
现在就用5分钟做这三件事:1. 打开文献文件夹,按"修改日期"排序,把陈年文献移出桌面
2. 选10篇最重要的文献,按标准重命名
3. 设置Windows文件历史备份
记住:如何保存文献PDF不是技术问题,而是知识管理的基础建设。
花1小时建立系统,未来能省100小时检索时间,这笔时间账怎么算都划算!
你在文献管理中还遇到过哪些抓狂的问题?欢迎在评论区分享,点赞最高的我会专门写续集解答~