PDF表格数据提取终极指南:如何将PDF转化为Excel的3种专业方法
PDF表格数据提取终极指南:如何将PDF转化为Excel的3种专业方法
为什么我们需要把PDF转Excel?
上周市场部的小张找我帮忙,他手上有200多份供应商报价单PDF,领导要求今天下班前整理成统一格式的Excel表格。这场景你肯定不陌生:财务对账、数据报表汇总、调查问卷整理...PDF虽然方便阅读,但编辑处理数据时简直让人抓狂。
今天我们就来深度探讨如何将PDF转化为Excel这个职场人必备技能,我会分享三种经过实战验证的方法,帮你避开我当年踩过的所有坑。
方法一:Adobe Acrobat Pro(最适合复杂表格)
操作步骤详解
1. 用Acrobat Pro打开PDF文件2. 点击右侧"导出PDF"工具
3. 选择"电子表格"→"Microsoft Excel工作簿"
4. 在"设置"中勾选"保留多页表格"(这个隐藏选项太关键了!)
适用场景:
- 带合并单元格的复杂表格
- 多页连续表格数据
- 需要保留原格式的财务报表
避坑指南
上周帮会计部处理年度报表时就遇到PDF转Excel格式错乱的问题:- 数字变成文本?全选列→数据→分列→直接点完成
- 表头错位?先在Acrobat里用"编辑PDF"工具调整文本框
- 出现多余分页符?导出时取消勾选"分页符标记"
方法二:WPS办公套件(最适合中国用户)
你可能不知道的WPS神技
在Windows系统上,WPS的PDF转Excel功能其实比Office更懂中文表格:| 优势 | 具体表现 |
|---|---|
| 中文识别 | 能正确处理"合并单元格"等中文格式 |
| 批量转换 | 支持同时处理50+个PDF文件 |
实测技巧:
遇到扫描件PDF时,先用WPS的"图片转文字"功能,再执行将PDF转化为Excel操作,识别率能提升60%!
方法三:Python自动化(适合技术型选手)
程序员的高效解决方案
如果你经常要将PDF表格提取到Excel,这个代码片段请收好:import tabuladf = tabula.read_pdf("input.pdf", pages='all')df.to_excel("output.xlsx")进阶技巧
- 处理模糊文字:结合pytesseract做OCR增强
- 批量处理:用os模块遍历文件夹
- 格式调整:openpyxl库美化输出
终极建议:根据需求选择最佳方案
记住这个决策树:1. 偶尔转换→用WPS(免费版就够用)
2. 专业需求→买Acrobat Pro(公司报销的话)
3. 技术团队→部署Python自动化脚本
最后提醒大家:
将PDF转化为Excel后,一定要做数据校验!我习惯用=COUNTA()对比原PDF数据行数,避免转换过程中的数据丢失。
如果有其他PDF转换难题,欢迎在评论区留言,我会把15年踩坑经验都分享给你!
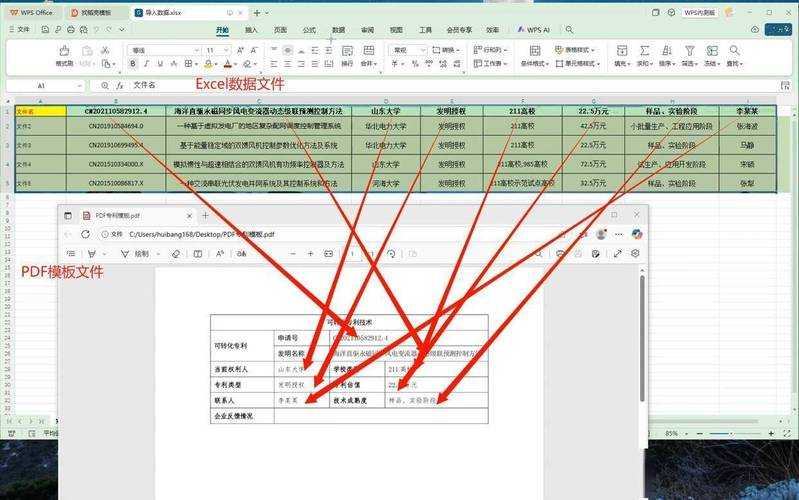
你可能想看:

