PDF文本提取终极指南:从基础操作到高阶技巧,90%的人都忽略了这些细节
PDF文本提取终极指南:从基础操作到高阶技巧,90%的人都忽略了这些细节
为什么你还在手动复制PDF文本?
上周我帮同事处理一份200页的技术文档,眼睁睁看着他Ctrl+C/V了整整一上午...其实PDF提取文本可以像喝水一样简单,今天我就把压箱底的6种方法全部分享给你,特别是最后一种,连扫描件都能搞定!
基础篇:人人都该掌握的3种PDF提取文本方法
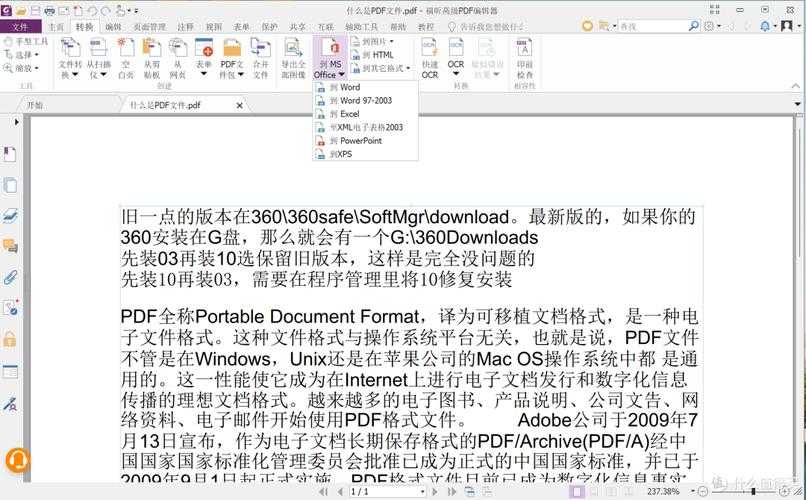
1. Adobe Acrobat官方解法(适合纯净版PDF)
在Windows系统上,按住Ctrl+O打开PDF后:- 点击右侧"工具"面板
- 选择"导出PDF"功能
- 将格式设为.txt或.docx
坑点:遇到加密PDF会提示输入密码(解决方法见第四章)
2. 浏览器大法(应急首选)
直接把PDF拖进Chrome浏览器:- 右键选择"打印"
- 目标位置选"另存为PDF"
- 用记事本打开新文件即可
3. 命令行黑科技(IT工程师必备)
在Windows PowerShell输入:pdftotext -layout 文件名.pdf 输出.txt需要先安装poppler-utils工具包,适合批量处理上百个PDF的自动化场景。
进阶篇:PDF提取文本的3个高阶姿势
4. OCR识别术(扫描件救星)
当你的PDF是扫描图片时:- OneNote:插入图片后右键"复制图片中的文本"
- 微信截图:Alt+A截取后点"文字识别"
- 专业方案:ABBYY FineReader(准确率高达99%)
5. Python自动化(批量处理神器)
用PyPDF2库三行代码搞定:import PyPDF2reader = PyPDF2.PdfReader("input.pdf")print(reader.pages[0].extract_text())配合Windows任务计划程序,可以实现每天自动提取邮件附件里的PDF报表。6. 在线工具链(跨平台方案)
| 工具名 | 特点 | 适用场景 |
|---|---|---|
| Smallpdf | 无需注册 | 临时使用 |
| iLovePDF | 支持API | 企业级应用 |
避坑指南:PDF提取文本常见问题解答
为什么提取的内容是乱码?
通常是字体嵌入问题,建议:1. 用Adobe Reader另存为"PDF/A"格式
2. 在Windows字体设置中安装文档所用字体
加密PDF怎么破解?
合法途径:用PDF Password Remover(需原始密码)灰色地带:在线解密工具存在隐私风险,不建议使用
终极建议:根据场景选择最佳PDF文本提取方案
- 日常办公:浏览器+微信截图组合拳
- 技术文档:Python脚本批量处理
- 扫描文件:ABBYY+人工校验
如果这篇PDF提取文本教程帮你省下了2小时,不妨点赞收藏,下次遇到同事还在手动复制时,潇洒地把这篇文章甩给他~