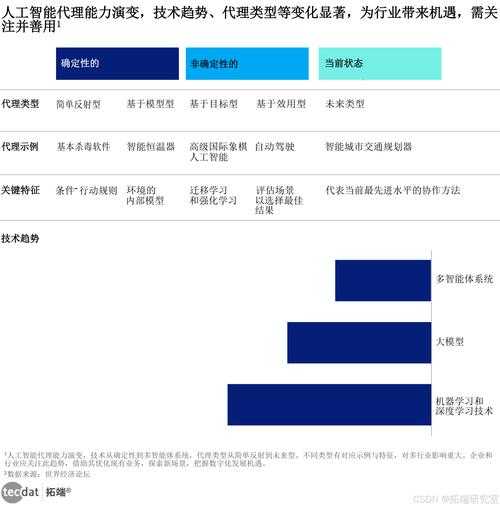
从技术视角解读:如何系统化应对不可预知的未来
从技术视角解读:如何系统化应对不可预知的未来
为什么技术人更需要读懂"黑天鹅"
大家好,我是你们的技术老友。今天想和大家聊聊一个看似与代码无关,但实际上每个技术人都应该深入思考的话题——如何应对不可预知的未来。记得有一次,我们团队精心规划了半年的项目,因为一个突如其来的政策变化几乎推倒重来。这种"黑天鹅事件"让我深刻意识到,仅仅做好技术规划是远远不够的。当我第一次接触到《黑天鹅:如何应对不可预知的未来》这本书时,突然有种豁然开朗的感觉。作者纳西姆·塔勒布提出的观点,其实与我们软件工程中的容错设计和系统冗余思想有着异曲同工之妙。今天我就结合自己的技术经验,和大家分享如何从系统化角度应对不确定性。
构建抗脆弱的技术体系
理解"黑天鹅事件"的本质特征
在技术领域,我们经常遇到的"黑天鹅事件"包括:- 突然的技术架构颠覆(比如某个核心框架停止维护)
- 意料之外的安全漏洞爆发
- 业务需求的剧烈变化
- 基础设施的突发故障
这些事件的共同特点就是不可预测但影响巨大。而《黑天鹅:如何应对不可预知的未来 pdf》中提出的核心理念,就是要我们建立一种能够从冲击中受益的系统。
Windows环境下的实践方案
在实际工作中,我发现Windows系统提供了一些很好的工具来帮助我们构建这样的系统:- 利用Windows的容器化技术:通过Docker Desktop可以在Windows环境下快速部署隔离的服务单元
- 系统还原点的智能设置:定期创建系统快照,确保在出现问题时能够快速回滚
- PowerShell自动化脚本:编写自动化的备份和监控脚本,降低人为失误的风险
特别是在处理《黑天鹅:如何应对不可预知的未来 pdf》中提到的"极端事件"时,Windows的可靠性表现让我印象深刻。其稳定的系统内核和完善的错误恢复机制,为应对不确定性提供了坚实的技术基础。
从代码到架构的容错设计
多层次防御策略
根据《黑天鹅:如何应对不可预知的未来 pdf》中的思想,我总结了一套技术实践方案:| 防御层级 | 具体措施 | Windows实现方案 |
|---|---|---|
| 代码层面 | 异常处理、输入验证 | 使用Visual Studio的调试工具 |
| 系统层面 | 服务监控、自动恢复 | Windows服务管理器的故障转移 |
| 架构层面 | 微服务、负载均衡 | IIS的应用程序池配置 |
这套方案的核心思想就是不要把所有鸡蛋放在一个篮子里,这也是《黑天鹅:如何应对不可预知的未来 pdf》反复强调的重点。
实际案例分析
去年我们遇到的一个典型"黑天鹅事件"是:某个第三方API服务突然变更接口,导致整个系统瘫痪。幸好我们提前做了以下准备:- 接口调用的超时设置和重试机制
- 本地缓存数据的fallback方案
- 实时监控告警系统
这些措施让我们在2小时内就恢复了服务,而不是像其他团队那样需要几天时间。这种应对不可预知的未来的能力,正是通过系统化建设获得的。
培养技术人的"反脆弱"思维
持续学习与技能多元化
在快速变化的技术领域,最大的风险就是技能单一化。《黑天鹅:如何应对不可预知的未来 pdf》中提到,要让自己在不确定性中成长,而不是仅仅追求稳定。我个人的做法是:
- 每月学习一项新技术或工具
- 参与开源项目,接触不同的技术栈
- 定期进行技术复盘和知识整理
这样的习惯让我在技术变革来临时能够快速适应,而不是被淘汰。
建立个人知识管理系统
对于《黑天鹅:如何应对不可预知的未来 pdf》这样的重要资料,我建议你建立数字化的知识库:- 使用OneNote进行读书笔记整理
- 通过Windows的索引服务快速检索资料
- 利用云同步确保数据安全
这种方法不仅适用于技术文档管理,也是应对知识爆炸时代的有效策略。
总结:从被动应对到主动布局
通过系统化地应用《黑天鹅:如何应对不可预知的未来 pdf》中的理念,我们能够将不可预知的风险转化为成长的机会。Windows平台提供的稳定性和丰富的工具生态,为我们构建抗脆弱系统提供了有力支持。记住,真正的安全不是避免变化,而是拥抱变化并在变化中成长。希望今天的分享能帮助你更好地应对技术道路上的各种"黑天鹅事件"。如果你有更好的经验或想法,欢迎在评论区交流讨论!