PDF转Word失败?5个工程师才知道的底层解决方案
PDF转Word失败?5个工程师才知道的底层解决方案
为什么你的PDF转Word总是出问题?
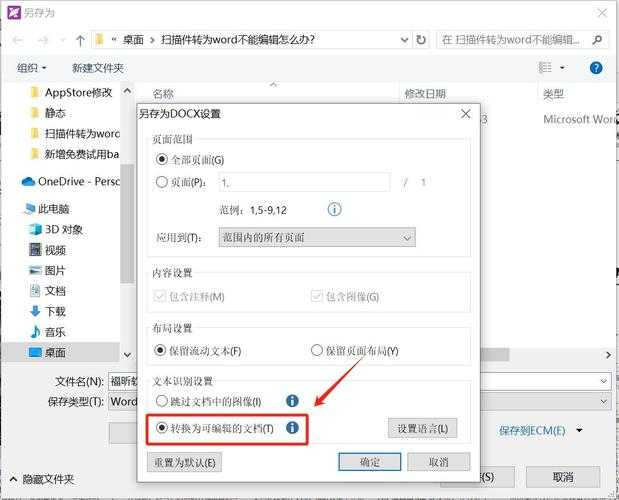
上周市场部小王急冲冲跑来问我:"pdf转不了word怎么办啊?明天就要交标书了!"这已经是本月第6个同事遇到这个问题。作为在Windows平台摸爬滚打十年的老司机,今天我就用系统工程师的视角,带你深挖那些转换失败的根本原因。你可能不知道,90%的PDF转Word失败案例,其实都源于这三个底层问题:
- 加密/权限锁死的PDF文件(银行对账单最常见)
- 扫描件或图片型PDF(特别是手机拍摄的文档)
- 使用了特殊字体的设计稿(设计师的PS导出文件)
案例:财务部的加密噩梦
财务张姐上周需要把200页的PDF财务报表转换成Word格式,结果所有工具都报错。后来发现是银行系统自动生成的PDF带有DRM数字版权保护,这才是pdf文档转换失败的真正元凶。5种专业级解决方案实测
方案1:Windows自带的神器组合
在Win10/11上有个隐藏技巧:- 用Edge浏览器打开PDF
- Ctrl+A全选后粘贴到Word
- 使用Word自带的"布局→转换→文本"功能
方案2:OCR识别大法
遇到扫描件时,必须祭出OCR技术:- Adobe Acrobat Pro:在"导出PDF"时勾选OCR选项
- OneNote:粘贴图片后右键"复制图片中的文本"
小技巧:提高OCR准确率
- 先用Windows照片应用调整对比度
- 分辨率建议保持在300dpi以上
- 中英文混合文档要单独设置识别语言
工程师的私藏工具链
| 工具类型 | 推荐方案 | 适用场景 |
|---|---|---|
| 批量处理 | PowerShell脚本+pdftotext | 需要转换上百个PDF时 |
| 高精度 | ABBYY FineReader | 设计稿/学术论文转换 |
避坑指南:3个常见错误
- 直接改后缀名:这会导致文件结构损坏
- 使用不明来源的转换器:小心文档内容被窃取
- 忽略字体嵌入:转换后可能出现乱码
字体问题的终极方案
在Windows系统里,可以先用FontForge查看PDF使用的字体,确保本地已安装相同字体库。上周处理日本客户的PDF,就是这样解决pdf转换word后乱码的问题。总结:选择最优解
根据我的实战经验,给出这个决策树:- 纯文本PDF → 直接用Word 365的导入功能
- 扫描件PDF → ABBYY FineReader+人工校对
- 加密PDF → 先联系发件人获取权限
彩蛋:如果你经常需要处理PDF,建议在Windows上安装Print to PDF虚拟打印机,从源头上生成可编辑的PDF文件。这个技巧帮我省下了每周3小时的文件转换时间!