PDF转Word怎么搞?从业十年老司机带你解锁五种终极方案
PDF转Word怎么搞?从业十年老司机带你解锁五种终极方案
一、为什么我们总在PDF和Word之间反复横跳?
你可能也遇到过这样的场景:市场部同事发来的合同PDF需要修改几个条款,学术论文的参考文献需要调整格式,或者客户给的宣传册PDF需要提取文字内容...PDF就像个顽固的保险箱,既保护了文档的完整性,又给我们日常编辑制造了障碍。这时候掌握PDF转Word怎么搞的实用技巧,就成了现代职场人的必修课。
1.1 那些年我们踩过的坑
上周公司新来的实习生小王,直接把扫描的PDF合同拖进在线转换工具,结果得到的Word文档全是乱码。市场总监李姐用微信传了个30页的产品手册PDF,转换后发现所有矢量图都变成了马赛克...
这些惨痛教训告诉我们:PDF转Word工具的选择和使用,绝对是个技术活。
二、五种实战方案深度评测
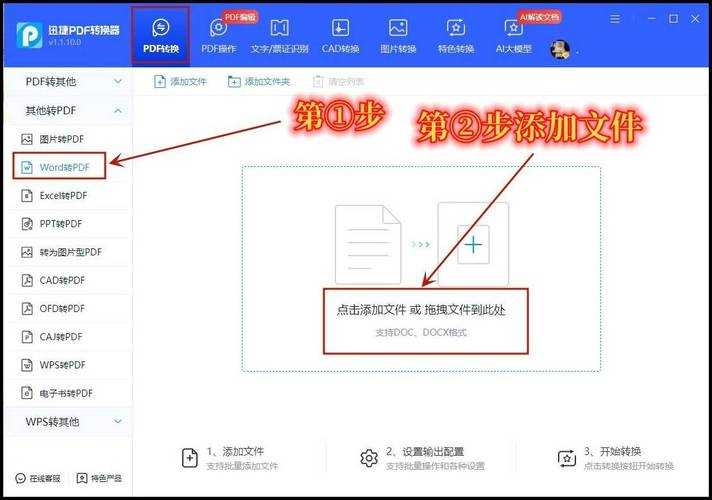
2.1 办公族必会的本地软件流
Window系统用户注意了!微软自带的Word 2013及以上版本就藏着个彩蛋:- 右键PDF文件 → 打开方式选择Word
- 等待自动转换提示
- 检查转换后的排版格式
| 步骤 | 耗时 | 效果 |
|---|---|---|
| 文件→打开PDF | 3秒 | 保留原始排版 |
| 输出为Word | 10秒/页 | 可编辑文字 |
| 格式微调 | 视复杂度 | 还原度90% |
2.2 程序员都在用的命令行大法
对于需要批量处理PDF转Word文档的技术控,推荐这个开源方案:pip install pdf2docximport pdf2docxparser = pdf2docx.Parser("input.pdf")parser.save("output.docx")这个方案的优势在于可以自定义转换精度,特别适合处理包含复杂表格的PDF文档。但需要提醒的是,扫描版PDF转换仍然需要OCR技术支持。三、老司机的私房避坑指南
3.1 扫描件转换的终极方案
当遇到扫描版PDF文档时,推荐使用ABBYY FineReader这类专业OCR工具。最近帮财务部转换2015年的扫描版合同时,我是这样操作的:- 预处理阶段:调整图像分辨率到300dpi
- 识别设置:指定中英混合识别模式
- 后处理:对比原PDF逐行校对
3.2 免费工具的隐藏风险
上周法务部有个紧急案例:某员工用不知名网站转换PDF,导致合同敏感信息泄露。这里分享三个安全准则:
- 优先选择本地化PDF转Word工具
- 检查网站是否HTTPS加密
- 转换后立即清除云端记录
四、不同场景的最佳实践
4.1 学术论文转换秘籍
帮研究生小张转换IEEE论文时发现:PDF转Word文档时要特别注意:
- 数学公式转换插件MathType
- 参考文献编号保护
- 矢量图转EMF格式
4.2 设计稿转换的黄金法则
去年帮市场部转换产品画册时总结的经验:PDF转Word工具处理图文混排时,务必:
- 先分离文字和图片层
- 转换后重建文字绕排
- 使用InDesign进行最终校对
五、未来已来的智能转换
最近测试的Window 11自带OCR功能让人惊艳:截图工具+Snipping Tool+Word的组合拳,能直接提取图片中的文字。
但要注意:这种方案对扫描版PDF转换的字号识别还不够精准,期待微软后续更新。
最后的建议:下次遇到PDF转Word怎么搞的难题时,先问自己三个问题:
1. 文档是文字版还是扫描版?
2. 需要保留多少原始格式?
3. 对信息安全的要求等级?
根据答案选择最适合的方案,毕竟在Window平台上,我们从来不缺好工具,缺的是对症下药的智慧。