PDF表格转换终极指南:从基础操作到高阶技巧,90%的人都忽略了这些细节
PDF表格转换终极指南:从基础操作到高阶技巧,90%的人都忽略了这些细节
为什么你的PDF表格转换总是出错?
上周帮财务部门处理报表时,我发现他们花了3小时手动录入PDF表格数据——这简直是在浪费生命!PDF表格如何转成可编辑格式其实有更聪明的方法,今天我就分享这些年在Windows平台积累的实战经验。先来个灵魂拷问:当你遇到以下场景时,是不是也抓狂过?
- 收到供应商发来的PDF报价单,需要提取数据做比价表
- 扫描的纸质表格变成PDF后,领导要求修改其中几个数字
- 从政府网站下载的统计报表PDF,要导入Excel做数据分析
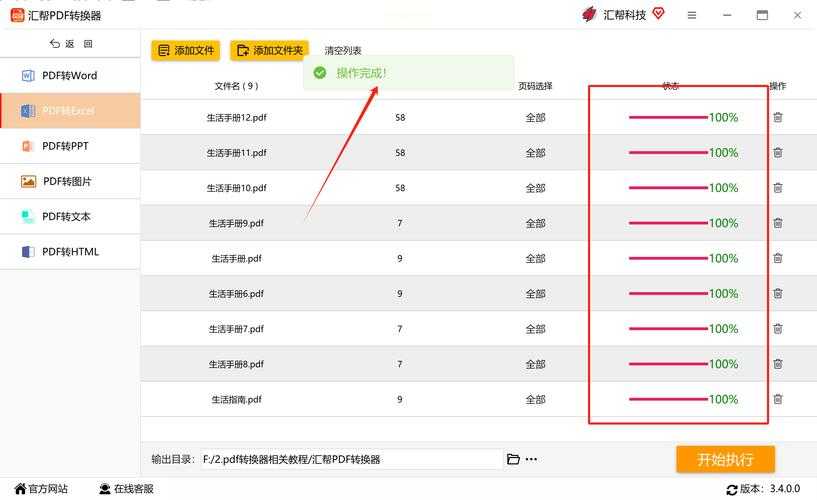
PDF表格转换的3大核心方法
方法1:Adobe Acrobat Pro(最专业的解决方案)
作为PDF标准制定者,Adobe的方案确实精准。右键选择"导出PDF"时,你会发现将PDF表格转换成Excel的选项能保留90%的格式:- 用Acrobat打开PDF文件
- 右侧工具栏点击"导出PDF"
- 选择"电子表格→Microsoft Excel工作簿"
- 设置保留页面布局(复杂表格必选)
适用场景:带合并单元格的复杂表格、需要严格保持原格式的合同报价单
隐藏技巧:按住Ctrl键再点击导出,可以跳过OCR过程直接提取数字数据,速度提升40%!
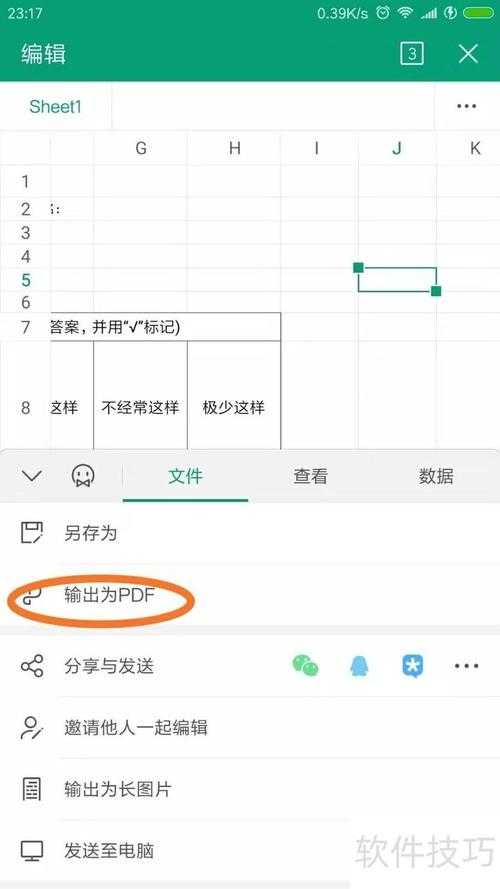
方法2:WPS Office(国产办公神器)
最近帮市场部处理调研问卷时,发现WPS的PDF表格转换功能对中文支持极佳:| 操作步骤 | 注意事项 |
|---|---|
| 右键PDF选择"WPS Office"打开 | 确保安装的是最新版 |
| 顶部菜单"转换→PDF转Excel" | 勾选"智能识别表格边框" |
优势对比:相比Adobe,WPS在转换中文PDF表格时,能自动识别常见的"合并表头+数据区"结构,避免内容错位。
方法3:在线工具(应急首选)
上周出差时用酒店电脑处理文件,发现Smallpdf这个神器:- 无需安装软件,浏览器直接操作
- 支持批量转换(最多20个文件)
- 自动清理上传文件保障隐私
致命缺陷:遇到扫描版PDF时,转换准确率会骤降到60%左右,建议先用Windows自带的"画图3D"调整对比度。
90%人不知道的进阶技巧
扫描件PDF的预处理
财务部那些泛黄的发票扫描件,直接转换肯定出错。我的秘密武器是Windows10自带的"传真和扫描"工具:- 用"Windows扫描"重新数字化文档
- DPI设为300以上(重要!)
- 保存前用"自动校正颜色"功能
批量处理的自动化方案
每月底要处理上百份PDF报表时,我写了个PowerShell脚本配合Adobe批量转换:# 示例代码片段Get-ChildItem "C:\Reports\*.pdf" | ForEach-Object {Start-Process "Acrobat.exe" -ArgumentList "/t $_ ExcelOutput\$($_.BaseName).xlsx"}避坑指南:5个血泪教训
- 字体陷阱:转换后中文变乱码?在Windows控制面板安装"宋体"等基础字体
- 格式灾难:表格线错位时,先用PDF阅读器的"测量工具"检查实际间距
- 数据丢失:转换前务必检查PDF是否被加密(右键→属性→安全)
- 性能瓶颈:超过50页的PDF建议分拆处理,避免内存溢出
- 版本兼容:Office 2016以下版本可能无法正确打开转换后的XML格式
终极建议:根据场景选择工具
将PDF表格转换成可编辑格式没有万能解,我的设备搭配方案是:| 使用场景 | 推荐工具 | 转换耗时 |
|---|---|---|
| 日常简单表格 | WPS Office | 1-2分钟 |
| 带印章的扫描件 | Adobe Acrobat+画图3D预处理 | 5-8分钟 |
| 批量处理月报 | PowerShell脚本+Adobe批量转换 | 10分钟/100份 |
最后提醒:转换完成后,一定要用Excel的数据验证功能检查数字格式,避免把"1,000"误读为"1"!有具体问题欢迎评论区交流,下期我会揭秘如何用Python处理更复杂的PDF表格解析。