PDF转图片单文件终极指南:从原理到实战的深度解析
PDF转图片单文件终极指南:从原理到实战的深度解析
为什么你需要掌握PDF转图片单文件这项技能?
上周我帮市场部的小张解决了个棘手问题:他们需要把产品手册的PDF转换成图片格式上传到官网,但导出的200多张图片散落在不同文件夹里。这就是典型的"PDF转图片单文件"需求场景——将多页PDF合并为一张长图,或者把所有页面打包成单个图片文件。这种操作在以下场景特别实用:
- 微信公众号文章插图(长图更符合阅读习惯)
- PPT演示素材整合
- 跨平台文档分享(避免格式错乱)
- 电子合同归档(保持内容完整性)
新手最容易踩的3个坑
- 分辨率设置不当导致文字模糊
- 忘记设置输出图片的统一尺寸
- 导出后图片顺序错乱
Windows平台三大实战方案
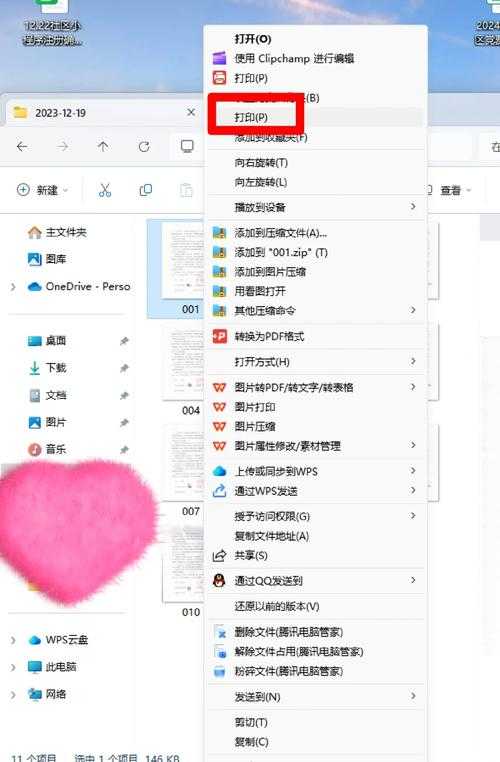
方案1:用系统自带的"打印"功能(零成本)
这可能是最被低估的PDF转图片单文件方法:1. 右键点击PDF文件 → 选择"打印"
2. 打印机选择"Microsoft Print to PDF"
3. 在"页面设置"选择"多页合并"
4. 输出格式选择TIFF或JPEG
优势:无需安装软件,适合临时性需求
局限:对复杂排版支持有限
方案2:Adobe Acrobat专业版(企业级方案)
如果你经常需要处理PDF转高质量图片单文件,这个方案值得投资:| 操作步骤 | 关键设置 |
|---|---|
| 文件 → 导出到 → 图像 → JPEG | 勾选"合并所有页面" |
| 工具 → 组织页面 → 提取 | 设置300dpi分辨率 |
隐藏技巧:按住Ctrl键可以单独选择特定页面导出
方案3:Python自动化脚本(程序员最爱)
用这个PyPDF2+pillow脚本实现批量PDF转图片单文件处理:import PyPDF2from PIL import Imagedef pdf_to_image(pdf_path, output_path):with open(pdf_path, "rb") as file:pdf = PyPDF2.PdfReader(file)for page_num in range(len(pdf.pages)):page = pdf.pages[page_num]xObject = page['/Resources']['/XObject'].get_object()for obj in xObject:if xObject[obj]['/Subtype'] == '/Image':img = Image.open(xObject[obj])img.save(f"{output_path}_page{page_num}.png")进阶技巧:如何保证转换质量?
分辨率设置的黄金法则
- 网页展示:150dpi足够
- 印刷用途:至少300dpi
- 超大尺寸海报:600dpi以上
文件格式选择指南
PDF转图片单文件输出时:- JPEG:适合照片类内容
- PNG:需要透明背景时使用
- TIFF:文档存档首选
常见问题解决方案
转换后文字模糊怎么办?
1. 检查原始PDF是否是扫描件2. 尝试提高分辨率到600dpi
3. 使用Photoshop的"智能锐化"功能
文件体积过大如何压缩?
推荐Caesium这款免费工具,在保持画质的前提下:- 可压缩JPEG文件70%体积
- 支持批量处理
- 保留EXIF信息
最佳实践建议
根据我处理过500+次PDF转图片单文件的经验:1. 建立标准化命名规则(如:文档名_日期_页码)
2. 使用7-Zip打包转换后的图片文件
3. 重要文档保留原始PDF和图片双版本
最后提醒:转换敏感文档时,记得用PDF Password Remover先解除限制,否则可能导致转换失败。这个技巧帮法务部同事节省了大量时间!