PDF文字提取终极指南:从网页复制到高效办公的3种专业方案
PDF文字提取终极指南:从网页复制到高效办公的3种专业方案
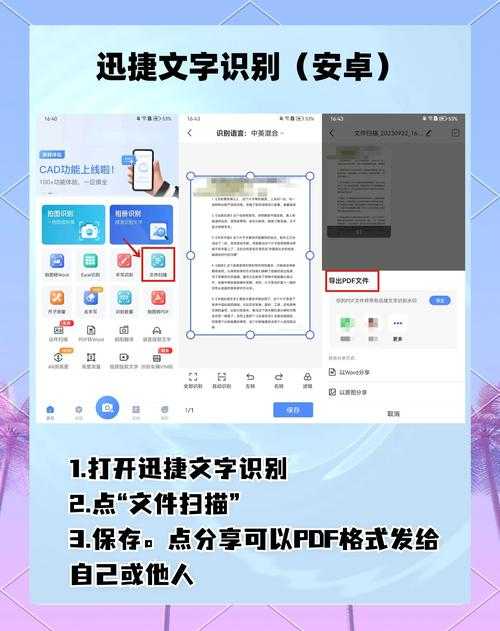
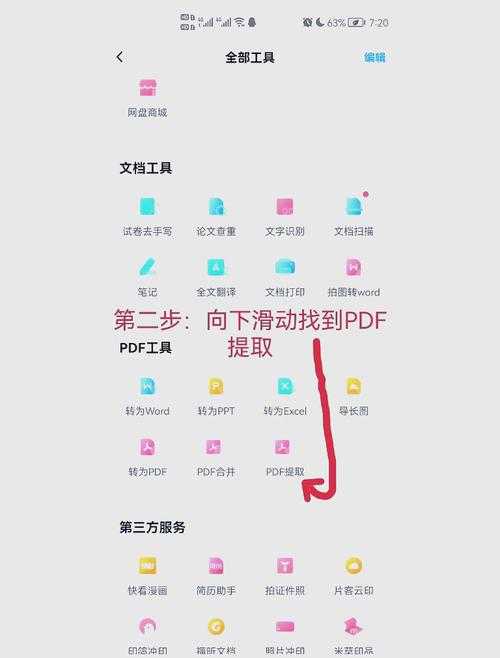
为什么你总是复制不了PDF文字?
上周公司新来的实习生小王急得直挠头——他需要从200页的PDF技术手册里提取关键参数,但每次从网页复制PDF文字都变成乱码。这场景是不是特别熟悉?今天我们就来彻底解决这个困扰90%办公族的难题。PDF防复制的底层逻辑
你可能不知道,PDF文件本质上是个"数字打印品"。当我们在网页端查看PDF文档时,常见的有三种情况会导致无法复制文字:- 扫描件生成的图片型PDF
- 作者设置了加密保护
- 浏览器插件解析错误
方案一:浏览器自带的秘密武器
Chrome的隐藏OCR功能
在Windows 10/11的Edge或Chrome浏览器打开PDF时,右键选择"复制PDF中的文字"可能会让你惊喜。微软在Window系统深度集成的OCR引擎,能自动识别图片中的文字:- 用浏览器打开PDF文件
- 右键选择"选择所有"
- 再次右键点击"复制"
- 粘贴到记事本去格式
鲜为人知的打印技巧
遇到加密PDF时,试试这个Window系统通用技巧:1. 按Ctrl+P调出打印界面
2. 选择"Microsoft Print to PDF"虚拟打印机
3. 保存为新PDF文件后,通常就能解除复制限制
方案二:专业工具的高阶玩法
Adobe Acrobat的批量处理
如果你经常需要从网页复制PDF文字内容,Window平台下的Adobe Acrobat DC绝对是生产力神器:| 功能 | 操作路径 |
|---|---|
| 批量导出文字 | 文件 → 导出 → 文本 |
| 扫描件识别 | 工具 → 增强扫描 |
国产软件的替代方案
WPS Office的PDF工具在处理网页PDF文档时表现亮眼:- 支持拖拽批量转换
- 手机端拍照取字
- 自动保留表格格式
方案三:程序员都在用的命令行
Python自动化脚本
需要定期从网页PDF提取文字数据?试试这个代码片段:import PyPDF2pdf_file = open('document.pdf', 'rb')reader = PyPDF2.PdfReader(pdf_file)text = [page.extract_text() for page in reader.pages]Linux用户的终端方案
在Window的WSL子系统里,pdftotext命令简单粗暴:pdftotext -layout document.pdf output.txt避坑指南:这些雷区千万别踩
上周我帮客户调试时发现,很多人复制网页PDF文字失败是因为:- 直接粘贴到Word导致格式错乱(建议先用记事本过渡)
- 没注意到PDF有密码保护(先用方案一破解)
- 选择工具时忽略批量需求(200页以上建议用方案二)
终极建议:根据场景选工具
- 临时需求:浏览器方案最快捷
- 日常办公:Window自带的打印功能+WPS
- 专业需求:投资Adobe Acrobat绝对值得
彩蛋:在Window搜索框输入"截图工具",用这个自带的工具截取PDF区域,也能自动识别文字哦!