从PDF到TXT:解锁文档编辑自由,资深工程师教你高效“汉 pdf转txt”
从PDF到TXT:解锁文档编辑自由,资深工程师教你高效“汉 pdf转txt”
前言:为什么你的PDF转TXT总是“乱码”?
作为一个在IT行业摸爬滚打十多年的老鸟,我见过太多同事和网友在处理“汉 pdf转txt”这个看似简单任务时翻车。你是不是也遇到过这种情况:- 好不容易转换出来的TXT文件,中文全是乱码
- 转换后格式全无,段落挤成一团
- 转换工具要么收费,要么功能受限
今天,我就从技术角度,结合window平台的优势,带你彻底解决这个痛点。这篇文章不仅告诉你方法,更会深入分析背后的原理,让你真正掌握“汉 pdf转txt”的精髓。
PDF转TXT的核心挑战:编码与格式的博弈
为什么中文PDF转TXT容易出问题?
PDF文件本质上是一个“印刷品”的数字化版本,它关注的是视觉效果而非内容结构。当你尝试将PDF转换为TXT时,实际上是在进行两个关键操作:- 文本提取 - 从PDF的复杂结构中识别并提取文字内容
- 编码转换 - 确保中文字符正确映射到TXT文件的编码体系
大多数“汉 pdf转txt”失败案例,问题都出在编码识别环节。PDF中的中文可能使用多种编码方式,如果转换工具无法正确识别,就会产生乱码。
window平台的优势在哪里?
在window系统环境下进行“汉 pdf转txt”操作有着天然优势:- 系统级的中文编码支持更加完善
- 大多数专业工具都优先开发window版本
- 系统API提供了丰富的文本处理功能
特别是对于需要批量处理“汉 pdf转txt”任务的用户,window平台的自动化脚本能力可以大幅提升效率。
实战方案:三种“汉 pdf转txt”方法深度评测
方法一:在线转换工具(适合轻度用户)
如果你只是偶尔需要处理“汉 pdf转txt”,在线工具是最便捷的选择。但需要注意:- 选择支持中文编码的知名平台
- 注意文件隐私安全,敏感文档慎用
- 免费版本通常有文件大小和数量限制
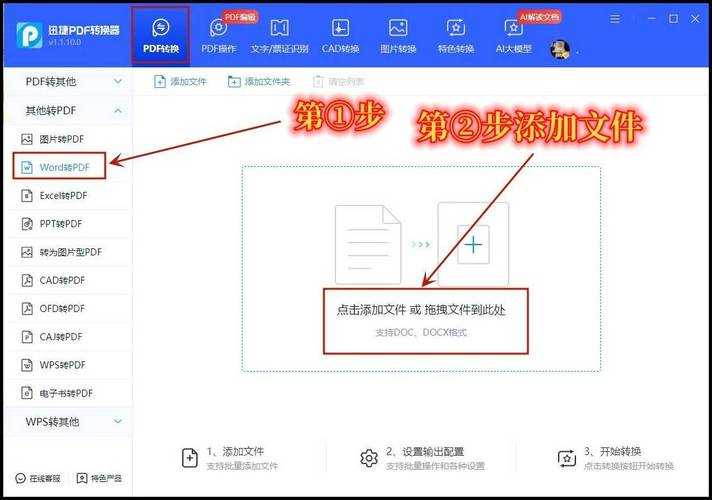
操作步骤:
1. 打开可靠的在线PDF转TXT网站
2. 上传你的PDF文件
3. 选择输出格式为TXT,确保编码设置为UTF-8
4. 下载转换后的文件并检查中文显示是否正确
这种方法适合处理单个小文件,但对于需要频繁进行“汉 pdf转txt”的专业用户来说,效率太低。
方法二:专业桌面软件(推荐重度用户)
对于需要经常处理“汉 pdf转txt”任务的用户,我强烈建议使用专业桌面软件。在window平台上,有几款工具表现出色:| 软件名称 | 优点 | 缺点 | 适合场景 |
|---|---|---|---|
| Adobe Acrobat Pro | 转换精度高,格式保留好 | 价格昂贵 | 企业级专业需求 |
| 福昕PDF编辑器 | 中文支持优秀,性价比高 | 功能相对基础 | 日常办公使用 |
| Smallpdf Desktop | 界面友好,操作简单 | 高级功能需付费 | 个人用户轻度使用 |
以福昕PDF编辑器为例的操作流程:
1. 在window系统安装福昕PDF编辑器
2. 打开需要转换的PDF文件
3. 选择“文件”→“导出为”→“文本文件”
4. 在设置中确保选择“Unicode (UTF-8)”编码
5. 根据需要调整布局保留选项
6. 点击“保存”完成转换
这种方法在“汉 pdf转txt”的准确性和效率方面都有很好表现,特别是对中文文档的支持相当成熟。
方法三:编程脚本方案(技术爱好者专属)
如果你有一定的编程基础,使用Python等语言自己写脚本处理“汉 pdf转txt”会是最灵活的方案。这种方法特别适合:- 需要批量处理大量PDF文件
- 有特定格式处理需求
- 希望将转换流程集成到其他自动化系统中
Python示例代码(使用pdfplumber库):
```python
import pdfplumber
def pdf_to_txt(pdf_path, txt_path):
with pdfplumber.open(pdf_path) as pdf:
text = ""
for page in pdf.pages:
text += page.extract_text() + "\n"
with open(txt_path, 'w', encoding='utf-8') as f:
f.write(text)
# 使用示例
pdf_to_txt('中文文档.pdf', '输出文件.txt')
```
这种方法在window环境下运行稳定,而且可以针对特定的“汉 pdf转txt”需求进行深度定制。
进阶技巧:提升“汉 pdf转txt”质量的实用建议
编码问题的终极解决方案
经过多年实践,我发现解决“汉 pdf转txt”编码问题最有效的方法是:- 优先选择支持UTF-8编码的转换工具
- 转换后使用Notepad++等文本编辑器检查编码
- 对于复杂文档,分批次转换测试最佳参数
特别是在window系统下,很多工具默认使用系统编码(如GBK),这是导致中文乱码的常见原因。强制使用UTF-8编码可以解决90%以上的问题。
格式保留的智能处理
单纯的“汉 pdf转txt”往往会导致格式丢失,通过以下技巧可以改善:- 在转换前对PDF进行OCR处理(针对扫描版PDF)
- 使用支持布局分析的转换工具
- 转换后使用正则表达式进行格式整理
对于需要在window平台进行大规模“汉 pdf转txt”处理的用户,我建议建立标准化的预处理流程,确保转换质量的一致性。
真实案例:我是如何用window工具链解决企业级“汉 pdf转txt”需求的
去年,我协助一家律师事务所处理上万份历史案卷的数字化工作。核心需求就是将扫描版PDF转换为可搜索的TXT文件,其中涉及大量中文内容。解决方案架构:
1. 使用window服务器搭建批量处理环境
2. 通过PowerShell脚本实现文件自动分發和调度
3. 结合Adobe Acrobat SDK和自定义Python脚本处理特殊格式
4. 建立质量检查流程确保“汉 pdf转txt”的准确性
这个案例证明,在window平台构建成熟的“汉 pdf转txt”工作流是完全可行的,关键是要选择合适的技术组合。
总结:选择适合你的“汉 pdf转txt”方案
无论你是偶尔需要转换几个文档的普通用户,还是需要处理大量PDF的专业人士,都能找到合适的“汉 pdf转txt”方案:- 轻度用户:选择可靠的在线工具,注意编码设置
- 常规用户:投资一款专业的PDF转换软件,提升工作效率
- 专业用户:在window平台构建自动化处理流程,实现规模化处理
记住,成功的“汉 pdf转txt”不仅取决于工具选择,更需要对中文编码和文档结构的深入理解。希望这篇文章能帮助你在下次遇到PDF转TXT需求时,能够游刃有余地解决问题。
如果你在实践过程中遇到其他问题,欢迎在评论区留言交流。作为技术博主,我会持续分享更多实用的软件使用技巧!
你可能想看:

