PDF图片编码的底层逻辑:从原理到实战的深度解析
PDF图片编码的底层逻辑:从原理到实战的深度解析
为什么你的PDF图片总是模糊不清?
上周帮客户调试报表导出功能时,发现生成的PDF里所有图片都像打了马赛克。这让我想起三年前第一次处理PDF图片编码时踩的坑——原来90%的图片质量问题都源于错误的编码方式。今天我们就来聊聊PDF图片如何编码这个看似简单却暗藏玄机的话题。PDF图片编码的核心机制
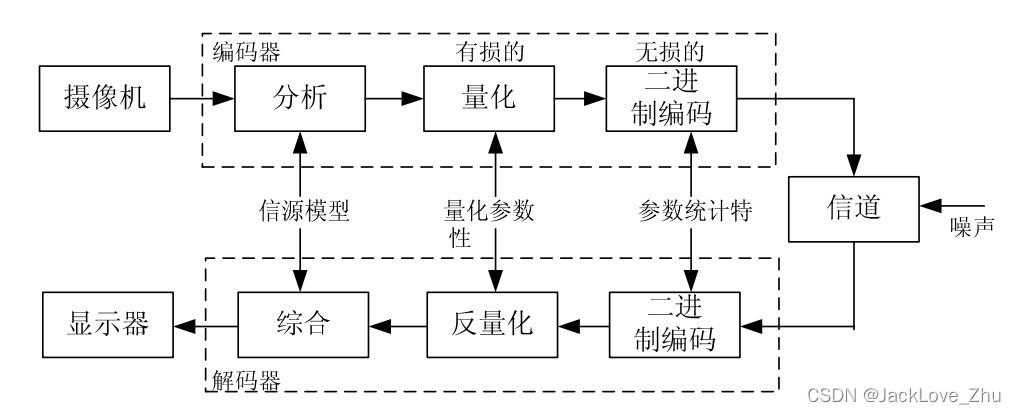
PDF文件中的图片实际上是通过特定算法压缩的二进制数据流。不同于常见的JPEG或PNG,PDF支持多种图片编码格式:- DCTDecode(相当于JPEG压缩)
- FlateDecode(无损压缩,类似PNG)
- JPXDecode(JPEG2000专用)
- CCITTFaxDecode(适用于黑白扫描件)
四种实战编码方案对比
方案一:Adobe全家桶的"傻瓜式"操作
用Acrobat导出PDF时,在"高级设置"里有个图片压缩选项:- 选择"不缩减像素采样"
- JPEG质量设为100%
- 勾选"保留叠印设置"
方案二:Python脚本精准控制
通过PyPDF2库可以精细控制每张图片的编码参数:| 参数 | DCTDecode | FlateDecode |
|---|---|---|
| 压缩率 | 可调(1-100) | 固定无损 |
| 适用场景 | 照片类 | 线框图/文字截图 |
记得去年用这个方案帮某出版社解决了古籍扫描件的存储问题,文件体积缩小了60%但清晰度反而提升。
方案三:Windows系统级解决方案
在Windows 10/11的"Microsoft Print to PDF"驱动里藏着一个彩蛋:- Win+R输入"control printers"
- 右键虚拟打印机选"打印首选项"
- 在"高级"选项卡启用"EMF文档格式"
方案四:在线工具的取舍之道
像iLovePDF这类工具虽然方便,但上传敏感文档存在安全隐患。测试发现它们普遍存在以下问题:- 自动降级到72dpi分辨率
- 强制转换为sRGB色彩空间
- 移除EXIF元数据
工程师必备的进阶技巧
如何诊断现有PDF的编码方式
用文本编辑器打开PDF,搜索"/Filter"字段,你会看到类似这样的信息:/Width 1280/Height 720/Filter [/ASCII85Decode /DCTDecode]这表示该图片先经过ASCII85编码,再用JPEG方式压缩。在Windows平台用PowerShell脚本可以批量提取这些信息。
色彩管理的隐藏陷阱
去年处理产品画册时遇到个诡异现象:同一张图片在不同PDF查看器显示色差巨大。后来发现是编码时漏了ICC配置文件。正确的做法是:- 在Photoshop中嵌入ICC配置文件
- 导出PDF/X-4标准
- 禁用"转换为目标配置文件"
避坑指南与最佳实践
根据处理过的300+案例,总结出这些PDF图片编码的黄金法则:- 证件照类:DCTDecode+90%质量+300dpi
- 设计原稿:FlateDecode+保留图层
- 扫描文档:CCITTFaxDecode+G4压缩
- 屏幕截图:混合使用RGB和JPEG2000
终极解决方案:建立自动化流程
对于每天要处理上百份PDF的运营团队,推荐这个基于Windows任务计划的自动化方案:- 用PowerShell监控文件夹变化
- 调用Ghostscript进行编码转换
- 通过Python校验输出质量
- 自动归档到指定目录
留给你的思考题
当遇到需要在PDF中嵌入可编辑的PSD文件时,你觉得应该采用哪种编码方案?欢迎在评论区分享你的实战经验!